International Journal of Parallel Programming ( IF 1.5 ) Pub Date : 2022-05-23 , DOI: 10.1007/s10766-022-00733-6 Sébastien Rivault , Mostafa Bamha , Sébastien Limet , Sophie Robert
|
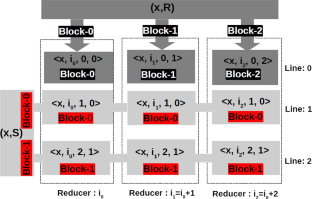
Similarity joins are recognized to be among the most useful data processing and analysis operations. A similarity join is used to retrieve all data pairs whose distances are smaller than a predefined threshold \(\lambda\). In this paper, we introduce the MRS-join algorithm to perform similarity joins on large trajectory datasets. The MapReduce model and a randomized local sensitive hashing keys redistribution approach are used to balance load among processing nodes while reducing communications and computations to almost all relevant data by using distributed histograms. A cost analysis of the MRS-join algorithm shows that our approach is insensitive to data skew and guarantees perfect balancing properties, in large scale systems, during all stages of similarity join computations. These performances have been confirmed by a series of experiments using the Fréchet distance on large datasets of trajectories from real world and synthetic data benchmarks.
中文翻译:
一种基于 MapReduce 和 LSH 的可扩展相似性连接算法
相似连接被认为是最有用的数据处理和分析操作之一。相似性连接用于检索距离小于预定义阈值\(\lambda\)的所有数据对。在本文中,我们介绍了MRS-join算法在大型轨迹数据集上执行相似性连接。MapReduce 模型和随机局部敏感散列键重新分配方法用于平衡处理节点之间的负载,同时通过使用分布式直方图减少对几乎所有相关数据的通信和计算。MRS-join的成本分析算法表明,我们的方法对数据倾斜不敏感,并保证在大规模系统中,在相似性连接计算的所有阶段都具有完美的平衡特性。这些性能已通过使用 Fréchet 距离对来自现实世界和合成数据基准的大型轨迹数据集进行的一系列实验得到证实。


























 京公网安备 11010802027423号
京公网安备 11010802027423号