Distributed Computing ( IF 1.3 ) Pub Date : 2022-05-26 , DOI: 10.1007/s00446-022-00427-9 El-Mahdi El-Mhamdi , Rachid Guerraoui , Arsany Guirguis , Lê-Nguyên Hoang , Sébastien Rouault
|
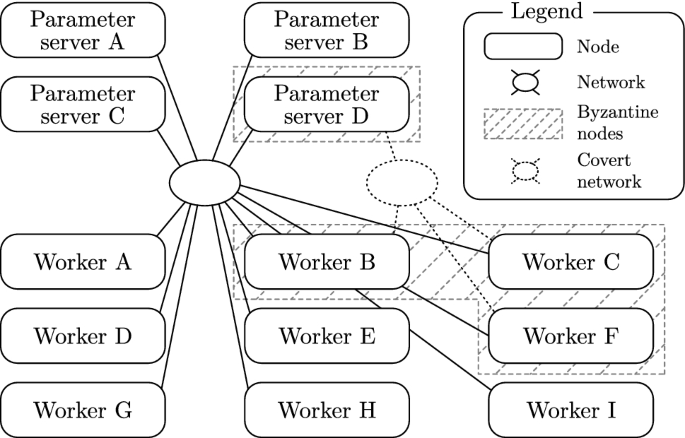
Machine learning (ML) solutions are nowadays distributed, according to the so-called server/worker architecture. One server holds the model parameters while several workers train the model. Clearly, such architecture is prone to various types of component failures, which can be all encompassed within the spectrum of a Byzantine behavior. Several approaches have been proposed recently to tolerate Byzantine workers. Yet all require trusting a central parameter server. We initiate in this paper the study of the “general” Byzantine-resilient distributed machine learning problem where no individual component is trusted. In particular, we distribute the parameter server computation on several nodes. We show that this problem can be solved in an asynchronous system, despite the presence of \(\frac{1}{3}\) Byzantine parameter servers (i.e., \(n_{ps} > 3f_{ps}+1\)) and \(\frac{1}{3}\) Byzantine workers (i.e., \(n_w > 3f_w\)), which is asymptotically optimal. We present a new algorithm, ByzSGD, which solves the general Byzantine-resilient distributed machine learning problem by relying on three major schemes. The first, scatter/gather, is a communication scheme whose goal is to bound the maximum drift among models on correct servers. The second, distributed median contraction (DMC), leverages the geometric properties of the median in high dimensional spaces to bring parameters within the correct servers back close to each other, ensuring safe and lively learning. The third, Minimum-diameter averaging (MDA), is a statistically-robust gradient aggregation rule whose goal is to tolerate Byzantine workers. MDA requires a loose bound on the variance of non-Byzantine gradient estimates, compared to existing alternatives [e.g., Krum (Blanchard et al., in: Neural information processing systems, pp 118-128, 2017)]. Interestingly, ByzSGD ensures Byzantine resilience without adding communication rounds (on a normal path), compared to vanilla non-Byzantine alternatives. ByzSGD requires, however, a larger number of messages which, we show, can be reduced if we assume synchrony. We implemented ByzSGD on top of both TensorFlow and PyTorch, and we report on our evaluation results. In particular, we show that ByzSGD guarantees convergence with around 32% overhead compared to vanilla SGD. Furthermore, we show that ByzSGD’s throughput overhead is 24–176% in the synchronous case and 28–220% in the asynchronous case.
中文翻译:
真正分布式拜占庭机器学习
根据所谓的服务器/工作者架构,机器学习 (ML) 解决方案现在是分布式的。一台服务器保存模型参数,而几个工作人员训练模型。显然,这种架构容易出现各种类型的组件故障,这些故障都可以包含在拜占庭行为的范围内。最近提出了几种方法来容忍拜占庭工人。然而,所有这些都需要信任一个中央参数服务器。我们在本文中启动了对“一般”拜占庭弹性的研究分布式机器学习问题,其中没有单个组件是可信的。特别是,我们将参数服务器计算分布在几个节点上。我们证明了这个问题可以在异步系统中解决,尽管存在\(\frac{1}{3}\)拜占庭参数服务器(即\(n_{ps} > 3f_{ps}+1\) ) 和\(\frac{1}{3}\)拜占庭工人(即\(n_w > 3f_w\)),这是渐近最优的。我们提出了一种新算法ByzSGD,它依靠三种主要方案解决了一般的拜占庭弹性分布式机器学习问题。第一种,分散/聚集, 是一种通信方案,其目标是在正确的服务器上限制模型之间的最大漂移。第二种,分布式中值收缩(DMC),利用高维空间中中值的几何特性,使正确服务器内的参数彼此靠近,确保安全和生动的学习。第三个,最小直径平均(MDA),是一种统计稳健的梯度聚合规则,其目标是容忍拜占庭工人。与现有的替代方案相比, MDA要求对非拜占庭梯度估计的方差有一个宽松的限制 [例如,Krum (Blanchard 等人,in: Neural information processing systems, pp 118-128, 2017)]。有趣的是,ByzSGD与普通的非拜占庭替代方案相比,无需添加通信轮次(在正常路径上)即可确保拜占庭弹性。然而, ByzSGD需要大量的消息,我们表明,如果我们假设同步,可以减少这些消息。我们在 TensorFlow 和 PyTorch 之上实现了ByzSGD,并报告了我们的评估结果。特别是,我们表明,与普通 SGD 相比, ByzSGD保证收敛约 32% 的开销。此外,我们表明ByzSGD的吞吐量开销在同步情况下为 24-176%,在异步情况下为 28-220%。


























 京公网安备 11010802027423号
京公网安备 11010802027423号