Annals of Dyslexia ( IF 2.275 ) Pub Date : 2022-06-10 , DOI: 10.1007/s11881-022-00261-5 Ashley A Edwards 1 , Wilhelmina van Dijk 1 , Christine M White 1 , Christopher Schatschneider 1
|
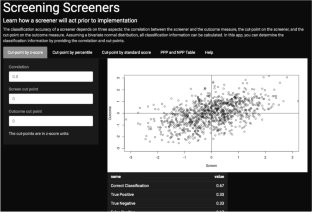
Given the recent push for universal screening, it is important to take into account how well a screener identifies children at risk for reading problems as well as how screener and sample information contribute to this classification. Picking the best cut-point for a particular sample and screening goal can be challenging given that test manuals often report classification information for a specific cut-point and sample base rate which may not generalize to other samples. By assuming a bivariate normal distribution, it is possible to calculate all of the classification information for a screener based on the correlation between the screener and outcome, the cut-point on the outcome (i.e., the base rate in the sample), and the cut-point on the screener. We provide an example with empirical data to validate these estimation procedures. This information is the basis for a free online tool that provides classification information for a given correlation between screener and outcome and cut-points on each. Results show that the correlation between screener and outcome needs to be greater than .9 (higher than observed in practice) to obtain good classification. These findings are important for researchers, administrators, and practitioners because current screeners do not meet these requirements. Since a correlation is dependent on the reliability of the measures involved, we need screeners with better reliability and/or multiple measures to increase reliability. Additionally, we demonstrate the impact of base rate on positive predictive power and discuss how gated screening can be useful in samples with low base rates.
中文翻译:
筛选筛选器:使用相关性和切点计算分类指数
鉴于最近推动全民筛查,重要的是要考虑筛查人员识别有阅读问题风险的儿童的能力以及筛查人员和样本信息如何有助于这种分类。考虑到测试手册经常报告特定切点和样本基本率的分类信息,而这些信息可能无法推广到其他样本,因此为特定样本和筛选目标选择最佳切点可能具有挑战性。通过假设二元正态分布,可以根据筛选者和结果之间的相关性、结果的切点(即样本中的基本率)和筛选器上的切点。我们提供了一个带有经验数据的示例来验证这些估计程序。该信息是免费在线工具的基础,该工具为筛选器和结果之间的给定相关性以及每个结果的切点提供分类信息。结果表明,筛选器与结果之间的相关性需要大于 0.9(高于实践中观察到的相关性)才能获得良好的分类。这些发现对于研究人员、管理人员和从业人员来说非常重要,因为当前的筛查人员不满足这些要求。由于相关性取决于所涉及措施的可靠性,因此我们需要具有更好可靠性的筛选器和/或多种措施来提高可靠性。此外,我们还展示了基础率对阳性预测能力的影响,并讨论了门控筛查如何在低基础率样本中发挥作用。


























 京公网安备 11010802027423号
京公网安备 11010802027423号