Information Retrieval Journal ( IF 2.5 ) Pub Date : 2022-08-06 , DOI: 10.1007/s10791-022-09414-x Lila Boualili , Jose G. Moreno , Mohand Boughanem
|
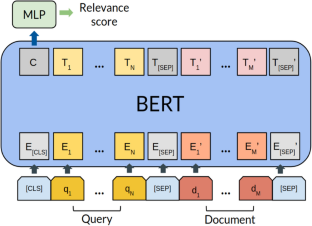
Pretrained language models (PLMs) exemplified by BERT have proven to be remarkably effective for ad hoc ranking. As opposed to pre-BERT models that required specialized neural components to capture different aspects of query-document relevance, PLMs are solely based on transformers where attention is the only mechanism used for extracting signals from term interactions. Thanks to the transformer’s cross-match attention, BERT was found to be an effective soft matching model. However, exact matching is still an essential signal for assessing the relevance of a document to an information-seeking query aside from semantic matching. We assume that BERT might benefit from explicit exact match cues to better adapt to the relevance classification task. In this work, we explore strategies for integrating exact matching signals using marker tokens to highlight exact term-matches between the query and the document. We find that this simple marking approach significantly improves over the common vanilla baseline. We empirically demonstrate the effectiveness of our approach through exhaustive experiments on three standard ad hoc benchmarks. Results show that explicit exact match cues conveyed by marker tokens are beneficial for BERT and ELECTRA variant to achieve higher or at least comparable performance. Our findings support that traditional information retrieval cues such as exact matching are still valuable for large pretrained contextualized models such as BERT.
中文翻译:
使用预训练的上下文语言模型通过标记策略突出显示精确匹配以进行临时文档排名
以 BERT 为代表的预训练语言模型 (PLM) 已被证明对临时排名非常有效。与需要专门的神经组件来捕获查询文档相关性的不同方面的预 BERT 模型相反,PLM 完全基于转换器,其中注意力是用于从术语交互中提取信号的唯一机制。由于 Transformer 的交叉匹配注意力,BERT 被发现是一种有效的软匹配模型。然而,除了语义匹配之外,精确匹配仍然是评估文档与信息搜索查询相关性的重要信号。我们假设 BERT 可能会受益于明确的精确匹配线索,以更好地适应相关性分类任务。在这项工作中,我们探索使用标记标记集成精确匹配信号的策略,以突出查询和文档之间的精确术语匹配。我们发现这种简单的标记方法比普通的普通基线显着改进。我们通过对三个标准临时基准的详尽实验,凭经验证明了我们方法的有效性。结果表明,标记标记传达的明确精确匹配提示有利于 BERT 和 ELECTRA 变体实现更高或至少相当的性能。我们的研究结果支持传统的信息检索线索(例如精确匹配)对于大型预训练的上下文模型(例如 BERT)仍然有价值。我们发现这种简单的标记方法比普通的普通基线显着改进。我们通过对三个标准临时基准的详尽实验,凭经验证明了我们方法的有效性。结果表明,标记标记传达的明确精确匹配提示有利于 BERT 和 ELECTRA 变体实现更高或至少相当的性能。我们的研究结果支持传统的信息检索线索(例如精确匹配)对于大型预训练的上下文模型(例如 BERT)仍然有价值。我们发现这种简单的标记方法比普通的普通基线显着改进。我们通过对三个标准临时基准的详尽实验,凭经验证明了我们方法的有效性。结果表明,标记标记传达的明确精确匹配提示有利于 BERT 和 ELECTRA 变体实现更高或至少相当的性能。我们的研究结果支持传统的信息检索线索(例如精确匹配)对于大型预训练的上下文模型(例如 BERT)仍然有价值。结果表明,标记标记传达的明确精确匹配提示有利于 BERT 和 ELECTRA 变体实现更高或至少相当的性能。我们的研究结果支持传统的信息检索线索(例如精确匹配)对于大型预训练的上下文模型(例如 BERT)仍然有价值。结果表明,标记标记传达的明确精确匹配提示有利于 BERT 和 ELECTRA 变体实现更高或至少相当的性能。我们的研究结果支持传统的信息检索线索(例如精确匹配)对于大型预训练的上下文模型(例如 BERT)仍然有价值。


























 京公网安备 11010802027423号
京公网安备 11010802027423号