GeoInformatica ( IF 2 ) Pub Date : 2023-01-16 , DOI: 10.1007/s10707-023-00486-5 Senlin Mu , Xiao Huang , Moyang Wang , Di Zhang , Dong Xu , Xiang Li
|
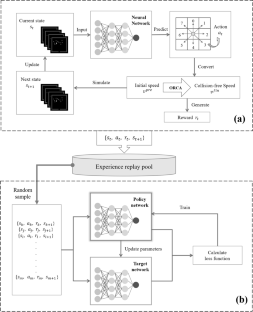
Most traditional pedestrian simulation methods suffer from short-sightedness, as they often choose the best action at the moment without considering the potential congesting situations in the future. To address this issue, we propose a hierarchical model that combines Deep Reinforcement Learning (DRL) and Optimal Reciprocal Velocity Obstacle (ORCA) algorithms to optimize the decision process of pedestrian simulation. For certain complex scenarios prone to local optimality, we include expert trajectory imitation degree in the reward function, aiming to improve pedestrian exploration efficiency by designing simple expert trajectory guidance lines without constructing databases of expert examples and collecting priori datasets. The experimental results show that the proposed method presents great stability and generalizability, evidenced by its capability to adjust the behavioral strategy earlier for the upcoming congestion situations. The overall simulation time for each scenario is reduced by approximately 8-44% compared to traditional methods. After including the expert trajectory guidance, the convergence speed of the model is greatly improved, evidenced by the reduced 56-64% simulation time from the first exploration to the global maximum cumulative reward value. The expert trajectory establishes the macro rules while preserving the space for free exploration, avoiding local dilemmas, and achieving optimized training efficiency.
中文翻译:
基于专家轨迹引导和深度强化学习优化行人模拟
大多数传统的行人模拟方法都存在短视问题,因为他们往往选择当下最好的行动,而没有考虑未来可能出现的拥堵情况。为了解决这个问题,我们提出了一种结合深度强化学习 (DRL) 和最佳倒数速度障碍 (ORCA) 算法的分层模型,以优化行人模拟的决策过程。对于某些容易出现局部最优的复杂场景,我们在奖励函数中加入了专家轨迹模仿度,旨在通过设计简单的专家轨迹引导线来提高行人探索效率,而无需构建专家示例数据库和收集先验数据集。实验结果表明,所提出的方法具有很好的稳定性和泛化性,它能够针对即将到来的拥堵情况更早地调整行为策略,这证明了这一点。与传统方法相比,每个场景的整体模拟时间减少了大约 8-44%。在加入专家轨迹引导后,模型的收敛速度大大提高,从第一次探索到全局最大累积奖励值的模拟时间减少了 56-64%。专家轨迹在建立宏观规则的同时保留了自由探索的空间,避免了局部困境,实现了优化的训练效率。在加入专家轨迹引导后,模型的收敛速度大大提高,从第一次探索到全局最大累积奖励值的模拟时间减少了 56-64%。专家轨迹在建立宏观规则的同时保留了自由探索的空间,避免了局部困境,实现了优化的训练效率。在加入专家轨迹引导后,模型的收敛速度大大提高,从第一次探索到全局最大累积奖励值的模拟时间减少了 56-64%。专家轨迹在建立宏观规则的同时保留了自由探索的空间,避免了局部困境,实现了优化的训练效率。


























 京公网安备 11010802027423号
京公网安备 11010802027423号