New Generation Computing ( IF 2.6 ) Pub Date : 2023-05-29 , DOI: 10.1007/s00354-023-00218-1 Deepti Sisodia , Dilip Singh Sisodia
|
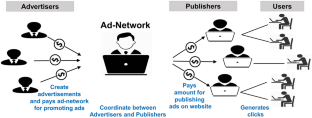
In online advertising, a change in the publisher’s actual status label with every generated click shows the suspicious behaviour of the publisher. Furthermore, only a small proportion of the clicks generated by the publishers are invalid, resulting in class skewness in the dataset and a challenging issue for the conventional classification methods as they get biased towards the outnumbered class. This suspicious behaviour of publishers with an uneven class distribution ratio adversely affects the classifier’s performance and increases model complexities. Thus, developing machine-learning methods capable of producing efficacious predictive models towards detecting fraudulent publishers is pivotal. This paper’s novel stacked generalization framework comprises two stacked generalization architectures, one for resampling and the second for classification. The framework employs a stacked generalization approach using generalizers to improve the learning model’s performance in two steps: first, reducing the error rate of algorithms towards reducing the bias in a learning set. Second, the results obtained through level-0 generalizers are fed as input to the level-1 generalizer with stacked integrated output towards combining the predictions for improving the predictive performance. Broad experimentations are conducted on FDMA 2012 user click dataset using ten-fold cross-validation. The performance of the proposed architecture is generalized by performing experiments on eight other highly imbalanced benchmark datasets, and performance is measured using average precision, recall, and F1-score. Results empirically prove the superiority of the proposed architecture in the publisher's behaviour prediction and classification as legitimate or illegitimate.
中文翻译:
用于从高度不平衡的用户点击数据集预测发布者行为的堆叠泛化架构,用于点击欺诈检测
在在线广告中,发布者的实际状态标签随每次生成的点击而发生变化,表明发布者的行为可疑。此外,发布者产生的点击中只有一小部分是无效的,这导致数据集中的类别偏斜,并且由于传统分类方法偏向于数量众多的类别,因此对传统分类方法来说是一个具有挑战性的问题。类分布比例不均匀的发布者的这种可疑行为会对分类器的性能产生不利影响并增加模型的复杂性。因此,开发能够生成有效预测模型以检测欺诈性发布者的机器学习方法至关重要。本文新颖的堆叠泛化框架包括两个堆叠泛化架构,一个用于重采样,第二个用于分类。该框架采用堆叠泛化方法,使用泛化器分两步提高学习模型的性能:首先,降低算法的错误率以减少学习集中的偏差。其次,将通过 0 级泛化器获得的结果作为输入提供给具有堆叠集成输出的 1 级泛化器,以组合预测以提高预测性能。使用十倍交叉验证对 FDMA 2012 用户点击数据集进行了广泛的实验。通过对其他八个高度不平衡的基准数据集进行实验来概括所提出架构的性能,并使用平均精度、召回率和 F1 分数来衡量性能。


























 京公网安备 11010802027423号
京公网安备 11010802027423号