Journal of Computer-Aided Molecular Design ( IF 3.5 ) Pub Date : 2023-06-17 , DOI: 10.1007/s10822-023-00512-6 Esben Jannik Bjerrum 1 , Christian Margreitter 1 , Thomas Blaschke 1 , Simona Kolarova 1 , Raquel López-Ríos de Castro 1, 2
|
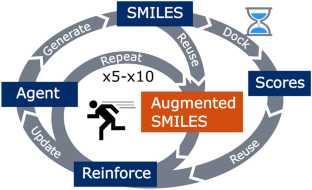
Using generative deep learning models and reinforcement learning together can effectively generate new molecules with desired properties. By employing a multi-objective scoring function, thousands of high-scoring molecules can be generated, making this approach useful for drug discovery and material science. However, the application of these methods can be hindered by computationally expensive or time-consuming scoring procedures, particularly when a large number of function calls are required as feedback in the reinforcement learning optimization. Here, we propose the use of double-loop reinforcement learning with simplified molecular line entry system (SMILES) augmentation to improve the efficiency and speed of the optimization. By adding an inner loop that augments the generated SMILES strings to non-canonical SMILES for use in additional reinforcement learning rounds, we can both reuse the scoring calculations on the molecular level, thereby speeding up the learning process, as well as offer additional protection against mode collapse. We find that employing between 5 and 10 augmentation repetitions is optimal for the scoring functions tested and is further associated with an increased diversity in the generated compounds, improved reproducibility of the sampling runs and the generation of molecules of higher similarity to known ligands.
中文翻译:
使用增强 SMILES 通过双环强化学习实现更快、更多样化的从头分子优化
结合使用生成深度学习模型和强化学习可以有效地生成具有所需特性的新分子。通过采用多目标评分函数,可以生成数千个高分分子,使这种方法可用于药物发现和材料科学。然而,这些方法的应用可能会受到计算成本昂贵或耗时的评分过程的阻碍,特别是当强化学习优化中需要大量函数调用作为反馈时。在这里,我们建议使用双环强化学习和简化分子线输入系统(SMILES)增强来提高优化的效率和速度。通过添加一个内部循环,将生成的 SMILES 字符串增强为非规范 SMILES,以便在额外的强化学习轮中使用,我们既可以在分子水平上重复使用评分计算,从而加快学习过程,并提供额外的保护模式崩溃。我们发现,采用 5 到 10 次增强重复对于测试的评分函数来说是最佳的,并且进一步与生成的化合物的多样性增加、采样运行的再现性提高以及与已知配体具有更高相似性的分子的生成相关。


























 京公网安备 11010802027423号
京公网安备 11010802027423号