当前位置:
X-MOL 学术
›
Comput. Animat. Virtual Worlds
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
CHAN: Skeleton based action recognition by multi-level feature learning
Computer Animation and Virtual Worlds ( IF 1.1 ) Pub Date : 2023-07-01 , DOI: 10.1002/cav.2193 Jian Lu 1 , Yinghao Gong 1 , Yanran Zhou 1 , Chengxian Ma 1 , Tingting Huang 1
Computer Animation and Virtual Worlds ( IF 1.1 ) Pub Date : 2023-07-01 , DOI: 10.1002/cav.2193 Jian Lu 1 , Yinghao Gong 1 , Yanran Zhou 1 , Chengxian Ma 1 , Tingting Huang 1
Affiliation
|
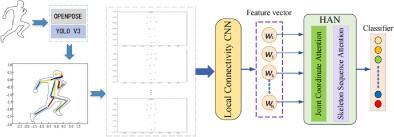
Skeleton-based action recognition has been continuously and intensively studied. However, dynamic 3D skeleton data are difficult to be popularized in practical applications due to the restricted data acquisition conditions. Although the action recognition method based on 2D pose information extracted from RGB video can effectively avoid the influence of complex background, it is susceptible to factors such as video jitter and joint overlap. To reduce the interference of the aforementioned factors, we use two-dimensional skeletal joint coordinate modal information to represent the changes in human body posture. First, we use a target detector and pose estimation algorithm to obtain the joint coordinates of each frame sample from RGB video. Then the feature extraction network is combined to perform multi-level feature learning to establish correspondence between actions and corresponding multi-level features. Finally, the hierarchical attention mechanism is introduced to design the model named CHAN. By calculating the association between elements, the weight of the action classification is redistributed. Extensive experiments on three datasets demonstrate the effectiveness of our proposed method.
中文翻译:

CHAN:通过多级特征学习进行基于骨架的动作识别
基于骨架的动作识别已经被不断深入地研究。然而,由于数据采集条件的限制,动态3D骨架数据在实际应用中很难普及。基于从RGB视频中提取的2D姿态信息的动作识别方法虽然可以有效避免复杂背景的影响,但容易受到视频抖动、关节重叠等因素的影响。为了减少上述因素的干扰,我们使用二维骨骼关节坐标模态信息来表示人体姿势的变化。首先,我们使用目标检测器和姿态估计算法从 RGB 视频中获取每个帧样本的关节坐标。然后结合特征提取网络进行多级特征学习,建立动作与对应多级特征之间的对应关系。最后,引入层次注意力机制设计模型CHAN。通过计算元素之间的关联度,重新分配动作分类的权重。对三个数据集的广泛实验证明了我们提出的方法的有效性。
更新日期:2023-07-01
中文翻译:
CHAN:通过多级特征学习进行基于骨架的动作识别
基于骨架的动作识别已经被不断深入地研究。然而,由于数据采集条件的限制,动态3D骨架数据在实际应用中很难普及。基于从RGB视频中提取的2D姿态信息的动作识别方法虽然可以有效避免复杂背景的影响,但容易受到视频抖动、关节重叠等因素的影响。为了减少上述因素的干扰,我们使用二维骨骼关节坐标模态信息来表示人体姿势的变化。首先,我们使用目标检测器和姿态估计算法从 RGB 视频中获取每个帧样本的关节坐标。然后结合特征提取网络进行多级特征学习,建立动作与对应多级特征之间的对应关系。最后,引入层次注意力机制设计模型CHAN。通过计算元素之间的关联度,重新分配动作分类的权重。对三个数据集的广泛实验证明了我们提出的方法的有效性。


























 京公网安备 11010802027423号
京公网安备 11010802027423号