International Journal of Parallel Programming ( IF 1.5 ) Pub Date : 2023-07-10 , DOI: 10.1007/s10766-023-00754-9 Vsevolod Bohaienko
|
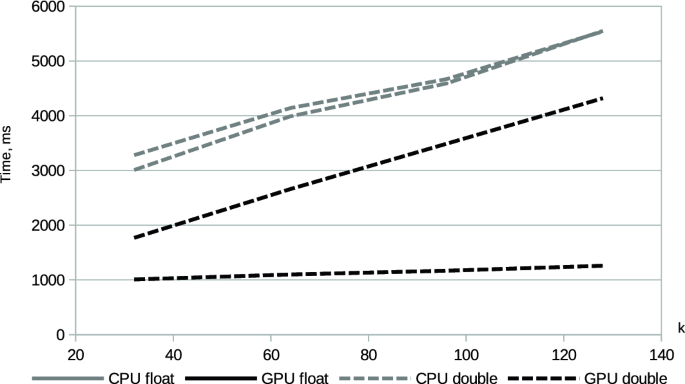
Due to an increased computational complexity of calculating the values of the distributed-order Caputo fractional derivative compared to the classical Caputo derivative there is a need to develop new techniques that accelerate it. In this paper for this purpose we propose to use a fast matrix "multiply and accumulate" operation available in GPU’s that contain the so-called tensor cores. We present and experimentally analyze the properties of GPU-algorithms that are based on the L1 finite-difference approximation of the derivative and incorporate them into the Crank-Nicholson scheme for the distributed-order time-fractional diffusion equation. The computation of derivative’s values on GPU was faster than the multi-threaded implementation on CPU only for a large number of time steps with growing performance gain when number of time steps increase. The usage of the single-precision data type increased the error up to \(2.7\%\) comparing with the usage of the double-precision data type. Half-precision computations in tensor cores increased the error up to \(29.5\%\). While solving a time-fractional diffusion equation, algorithms implemented for GPU with the usage of the single-precision data type were at least three times faster than the CPU-implementation for the number of time steps more than 1280. Data type precision had only slight influence on the solution error with significantly increased execution time when the double-precision data type was used for data storage and processing.
中文翻译:
在支持 Tensor Core 的 GPU 上计算分布式阶分数导数
由于与经典 Caputo 导数相比,计算分布式 Caputo 分数导数的值的计算复杂性增加,因此需要开发加速它的新技术。为此,在本文中,我们建议使用包含所谓张量核心的 GPU 中可用的快速矩阵“乘法和累加”运算。我们提出并通过实验分析了基于导数的 L1 有限差分近似的 GPU 算法的属性,并将它们合并到分布阶时间分数扩散方程的 Crank-Nicholson 格式中。仅在大量时间步长时,GPU 上导数值的计算才比 CPU 上的多线程实现更快,并且当时间步数增加时性能增益不断增加。使用单精度数据类型将误差增加到与双精度数据类型的使用相比\(2.7\%\) 。张量核心中的半精度计算将误差增加到\(29.5\%\)。在求解时间分数扩散方程时,对于时间步数超过 1280 的情况,使用单精度数据类型为 GPU 实现的算法至少比 CPU 实现快三倍。数据类型精度仅略有提高当使用双精度数据类型进行数据存储和处理时,执行时间显着增加,对求解误差产生影响。


























 京公网安备 11010802027423号
京公网安备 11010802027423号