Programming and Computer Software ( IF 0.7 ) Pub Date : 2023-07-28 , DOI: 10.1134/s0361768823040138 K. Avetisyan , G. Gritsay , A. Grabovoy
|
Abstract
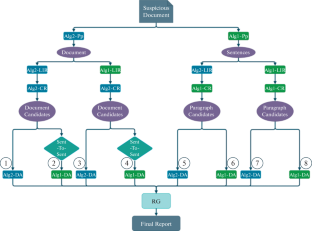
The widespread availability of scientific documents in multiple languages, coupled with the development of automatic translation and editing tools, has created a demand for efficient methods that can detect plagiarism across different languages. In this paper, we present a novel cross-lingual plagiarism detection approach. The algorithm is based on the merger of two existing approaches that in turn achieve state-of-the-art (SOTA) or comparable to SOTA results on different benchmarks. The detailed analysis stages of existing approaches were sequentially merged levelling out the disadvantages of the approaches. The obtained algorithm significantly outperforms the ones it was merged of surpassing them by from 23 to 33% Plagdet Score, depending on different language pairs. The comparison between observed approaches was evaluated on a newly generated multilingual (English, Russian, Spanish, Armenian) test collection, where each suspicious document could contain plagiarised fragments from several languages. The merged method is applicable to various under-resourced languages which is shown on the example of the Armenian language.
中文翻译:
跨语言抄袭检测:两项优于一项
摘要
多种语言的科学文献的广泛使用,加上自动翻译和编辑工具的发展,产生了对能够检测不同语言的抄袭行为的有效方法的需求。在本文中,我们提出了一种新颖的跨语言抄袭检测方法。该算法基于两种现有方法的合并,从而实现了最先进的 (SOTA) 或与不同基准上的 SOTA 结果相当。现有方法的详细分析阶段依次合并,以消除这些方法的缺点。所获得的算法明显优于合并后的算法,根据不同的语言对,Plagdet 分数比它们高出 23% 到 33%。观察到的方法之间的比较是在新生成的多语言(英语、俄语、西班牙语、亚美尼亚语)测试集合上进行评估的,其中每个可疑文档都可能包含来自多种语言的抄袭片段。合并方法适用于各种资源贫乏语言,如亚美尼亚语所示。


























 京公网安备 11010802027423号
京公网安备 11010802027423号