World Wide Web ( IF 3.7 ) Pub Date : 2023-08-03 , DOI: 10.1007/s11280-023-01199-3 Xiaoxiao Xie , Shengfei Shi , Hongzhi Wang , Mohan Li
|
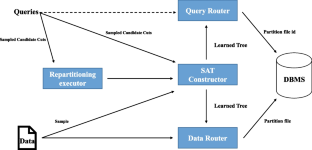
Nowadays, the volume of online data stored on websites is constantly increasing, and users’ demand for faster query response times is also on the rise with the expansion of network bandwidth. To improve the efficiency of database query, many large enterprises use database partitioning to divide huge database tables and speed up query results. While database partitioning methods based on query workloads have been successful, they have their limitations. These methods rely heavily on current workloads and the resulting partitioning structures may need to be improved when workloads change, a process called database repartitioning. Most current methods for repartitioning involve restarting the partitioning module directly, leading to significant overhead in industry due to the high complexity of the partitioning algorithm. Additionally, existing repartitioning models are often artificially determined and cannot achieve truly adaptive repartitioning. To address these issues, we propose a multi-tree training sampling model based on existing tree-shaped structure, which can speed up qdtree partitioning algorithm and reduce overhead caused by repartitioning. We also introduce improvements to qdtree structure to make it more adaptable to our method. For each query received by the partitioning model, we use a result-return rate mechanism to accumulate the evaluation of the current query on the partition structure, and initiate repartitioning only after a certain threshold is reached. Furthermore, we use the data redundancy storage technique to further improve query speed.
中文翻译:
SAT:自适应数据库重新分区的采样加速树
如今,网站上存储的在线数据量不断增加,用户对更快的查询响应时间的需求也随着网络带宽的扩展而不断上升。为了提高数据库查询的效率,很多大型企业使用数据库分区来划分庞大的数据库表,加快查询结果。虽然基于查询工作负载的数据库分区方法已经取得了成功,但它们也有其局限性。这些方法严重依赖于当前的工作负载,当工作负载发生变化时,可能需要改进生成的分区结构,这一过程称为数据库重新分区。目前大多数重新分区的方法都是直接重启分区模块,由于分区算法的复杂性较高,导致工业上的开销很大。此外,现有的重分区模型往往是人为确定的,无法实现真正的自适应重分区。为了解决这些问题,我们提出了一种基于现有树形结构的多树训练采样模型,可以加速qdtree分区算法并减少重新分区带来的开销。我们还对 qdtree 结构进行了改进,使其更适合我们的方法。对于分区模型收到的每个查询,我们使用结果返回率机制来累积当前查询对分区结构的评估,并仅在达到某个阈值后才启动重新分区。此外,我们使用数据冗余存储技术来进一步提高查询速度。为了解决这些问题,我们提出了一种基于现有树形结构的多树训练采样模型,可以加速qdtree分区算法并减少重新分区带来的开销。我们还对 qdtree 结构进行了改进,使其更适合我们的方法。对于分区模型收到的每个查询,我们使用结果返回率机制来累积当前查询对分区结构的评估,并仅在达到某个阈值后才启动重新分区。此外,我们使用数据冗余存储技术来进一步提高查询速度。为了解决这些问题,我们提出了一种基于现有树形结构的多树训练采样模型,可以加速qdtree分区算法并减少重新分区带来的开销。我们还对 qdtree 结构进行了改进,使其更适合我们的方法。对于分区模型收到的每个查询,我们使用结果返回率机制来累积当前查询对分区结构的评估,并仅在达到某个阈值后才启动重新分区。此外,我们使用数据冗余存储技术来进一步提高查询速度。我们还对 qdtree 结构进行了改进,使其更适合我们的方法。对于分区模型收到的每个查询,我们使用结果返回率机制来累积当前查询对分区结构的评估,并仅在达到某个阈值后才启动重新分区。此外,我们使用数据冗余存储技术来进一步提高查询速度。我们还对 qdtree 结构进行了改进,使其更适合我们的方法。对于分区模型收到的每个查询,我们使用结果返回率机制来累积当前查询对分区结构的评估,并仅在达到某个阈值后才启动重新分区。此外,我们使用数据冗余存储技术来进一步提高查询速度。


























 京公网安备 11010802027423号
京公网安备 11010802027423号