Circuits, Systems, and Signal Processing ( IF 2.3 ) Pub Date : 2024-02-01 , DOI: 10.1007/s00034-023-02480-6 Jiu Sun , Jinxin Zhu , Jun Shao
|
Abstract
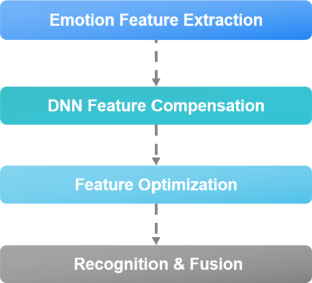
In this paper, we study the speech emotion feature optimization using stochastic optimization algorithms, and feature compensation using deep neural networks. We also proposed to use accentuation-based fusion for long-time speech emotion recognition. Firstly, the extraction method of emotional features is studied, and a series of speech features are constructed for the recognition of emotion. Secondly, we propose a method of sample adaptation through denoising autoencoder to enhance the versatility of features through the mapping of sample features to improve adaptive ability. Thirdly, GA and SFLA are used to optimize the combination of features to improve the emotion recognition results at the utterance level. Finally, we use transformer model to implement accentuation-based emotion fusion in long-time speech. The continuous long-time speech corpus, as well as the public available EMO-DB, are used for experiments. Results show that the proposed method can effectively improve the performance of long-time speech emotion recognition.
中文翻译:
使用特征补偿和基于重音的融合进行长时间语音情感识别
摘要
在本文中,我们研究使用随机优化算法的语音情感特征优化,以及使用深度神经网络的特征补偿。我们还建议使用基于重音的融合进行长时间语音情感识别。首先研究了情感特征的提取方法,构建了一系列语音特征用于情感识别。其次,我们提出了一种通过去噪自编码器进行样本自适应的方法,通过样本特征的映射来增强特征的通用性,从而提高自适应能力。第三,利用GA和SFLA来优化特征组合,以提高话语层面的情感识别结果。最后,我们使用 Transformer 模型在长时间语音中实现基于重音的情感融合。使用连续长时间语音语料库以及公开可用的EMO-DB进行实验。结果表明,该方法能够有效提高长时间语音情感识别的性能。


























 京公网安备 11010802027423号
京公网安备 11010802027423号