Applied Mathematics and Optimization ( IF 1.8 ) Pub Date : 2023-09-20 , DOI: 10.1007/s00245-023-10058-6 Jean-François Aujol , Charles Dossal , Van Hao Hoàng , Hippolyte Labarrière , Aude Rondepierre
|
First-order optimization algorithms can be considered as a discretization of ordinary differential equations (ODEs) (Su et al. in Adv Neural Inf Process Syst 27, 2014). In this perspective, studying the properties of the corresponding trajectories may lead to convergence results which can be transfered to the numerical scheme. In this paper we analyse the following ODE introduced by Attouch et al. (J Differ Equ 261(10):5734–5783, 2016):
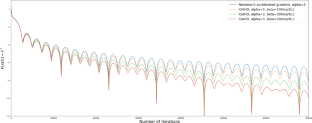
$$\begin{aligned} \forall t\geqslant t_0,~\ddot{x}(t)+\frac{\alpha }{t}{\dot{x}}(t)+\beta H_F(x(t)){\dot{x}}(t)+\nabla F(x(t))=0, \end{aligned}$$where \(\alpha >0\), \(\beta >0\) and \(H_F\) denotes the Hessian of F. This ODE can be derived to build numerical schemes which do not require F to be twice differentiable as shown in Attouch et al. (Math Program 1–43, 2020) and Attouch et al. (Optimization 72:1–40, 2021). We provide strong convergence results on the error \(F(x(t))-F^*\) and integrability properties on \(\Vert \nabla F(x(t))\Vert \) under some geometry assumptions on F such as quadratic growth around the set of minimizers. In particular, we show that the decay rate of the error for a strongly convex function is \(O(t^{-\alpha -\varepsilon })\) for any \(\varepsilon >0\). These results are briefly illustrated at the end of the paper.
中文翻译:
几何假设下惯性动力学与 Hessian 驱动阻尼的快速收敛
一阶优化算法可以被视为常微分方程 (ODE) 的离散化(Su 等人,Adv Neural Inf Process Syst 27, 2014)。从这个角度来看,研究相应轨迹的性质可能会导致收敛结果,并将其转移到数值格式中。在本文中,我们分析了 Attouch 等人提出的以下 ODE。(J Differ Equ 261(10):5734–5783, 2016):
$$\begin{对齐} \forall t\geqslant t_0,~\ddot{x}(t)+\frac{\alpha }{t}{\dot{x}}(t)+\beta H_F(x( t)){\dot{x}}(t)+\nabla F(x(t))=0, \end{对齐}$$其中\(\alpha >0\)、\(\beta >0\)和\(H_F\)表示F的 Hessian 矩阵。可以导出此 ODE 来构建不需要F两次可微的数值方案,如 Attouch 等人所示。(数学计划 1-43,2020 年)和 Attouch 等人。(优化 72:1-40,2021)。我们在F的一些几何假设下提供了误差\(F(x(t))-F^*\) 的强收敛结果和\(\Vert \nabla F(x(t))\Vert \)上的可积性属性例如围绕最小化集的二次增长。特别地,我们证明强凸函数的误差衰减率为\(O(t^{-\alpha -\varepsilon })\)对于任何\(\varepsilon >0\)。这些结果在本文末尾进行了简要说明。


























 京公网安备 11010802027423号
京公网安备 11010802027423号