Genetic Programming and Evolvable Machines ( IF 2.6 ) Pub Date : 2023-09-19 , DOI: 10.1007/s10710-023-09456-0 Mathias K. Nilsen , Tønnes F. Nygaard , Kai Olav Ellefsen
|
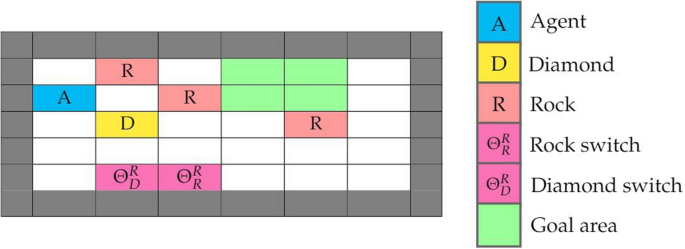
Reward tampering is a problem that will impact the trustworthiness of the powerful AI systems of the future. Reward Tampering describes the problem where AI agents bypass their intended objective, enabling unintended and potentially harmful behaviours. This paper investigates whether the creative potential of evolutionary algorithms could help ensure trustworthy solutions when facing this problem. The reason why evolutionary algorithms may help combat reward tampering is that they are able to find a diverse collection of different solutions to a problem within a single run, aiding the search for desirable solutions. Four different evolutionary algorithms were deployed in tasks illustrating the problem of reward tampering. The algorithms were designed with varying degrees of human expertise, measuring how human guidance influences the ability to discover trustworthy solutions. The results indicate that the algorithms’ ability to find and preserve trustworthy solutions is very dependent on preserving diversity during the search. Algorithms searching for behavioural diversity showed to be the most effective against reward tampering. Human expertise also showed to improve the certainty and quality of safe solutions, but even with only a minimal degree of human expertise, domain-independent diversity management was found to discover safe solutions.
中文翻译:
奖励篡改和进化计算:使用进化算法研究具体的人工智能安全问题
奖励篡改是一个将影响未来强大人工智能系统可信度的问题。奖励篡改描述了人工智能代理绕过其预期目标,导致意外和潜在有害行为的问题。本文研究了进化算法的创造性潜力是否有助于确保在面对这个问题时提供值得信赖的解决方案。进化算法之所以有助于对抗奖励篡改,是因为它们能够在一次运行中找到问题的多种不同解决方案,从而帮助寻找理想的解决方案。在说明奖励篡改问题的任务中部署了四种不同的进化算法。这些算法是根据不同程度的人类专业知识设计的,衡量人类指导如何影响发现值得信赖的解决方案的能力。结果表明,算法找到并保留可信解决方案的能力很大程度上取决于搜索过程中保留多样性。寻找行为多样性的算法被证明是对抗奖励篡改最有效的方法。人类专业知识也表明可以提高安全解决方案的确定性和质量,但即使只有最低程度的人类专业知识,独立于领域的多样性管理也可以发现安全解决方案。


























 京公网安备 11010802027423号
京公网安备 11010802027423号