Information Retrieval Journal ( IF 2.5 ) Pub Date : 2023-10-02 , DOI: 10.1007/s10791-023-09420-7 Sumam Francis , Marie-Francine Moens
|
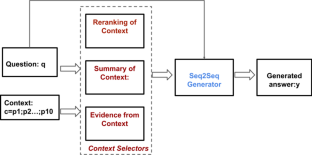
Generating natural language answers for question-answering (QA) tasks has recently surged in popularity with the rise of task-based personalized assistants. Most QA research is on extractive QA, methods that find answer spans in text passages. However, the extracted answers are often incomplete and sound unnatural in a conversational context. In contrast, generative QA systems aim to generate well-formed natural language answers. For this type of QA, the answer generation method and context play crucial roles in the model performance. A challenge of generative QA is simultaneously incorporating all facts in the context necessary to answer the question and discarding irrelevant information. In this paper, we investigate efficient ways to utilize the context and to generate better contextual answers. We present a framework for generative QA that effectively selects relevant parts from context documents by eliminating extraneous information. We first present multiple strong generative baselines that use transformer-based encoder-decoder architectures to synthesize answers. These models perform equal to or better than the current state-of-the-art generative models. We next investigate the selection of relevant information from context. The context selector component can be a summarizer, reranker, evidence extractor or a combination of these. Finally, we effectively use this filtered context information to provide the most pertinent cues to the generative model to synthesize factually correct natural language answers. This significantly boosts the model’s performance. The setting with the reranked context together with evidence gives the best performance. We also study the impact of different training strategies on the answer generation capability.
中文翻译:
研究生成式问答的更好上下文表示
随着基于任务的个性化助理的兴起,为问答 (QA) 任务生成自然语言答案最近越来越受欢迎。大多数 QA 研究都是关于提取式 QA,即在文本段落中查找答案范围的方法。然而,提取的答案通常不完整,并且在对话环境中听起来不自然。相比之下,生成式问答系统旨在生成格式良好的自然语言答案。对于这种类型的 QA,答案生成方法和上下文在模型性能中起着至关重要的作用。生成式 QA 的挑战是同时将所有事实纳入回答问题所需的上下文中,并丢弃不相关的信息。在本文中,我们研究了利用上下文并生成更好的上下文答案的有效方法。我们提出了一个生成式 QA 框架,通过消除无关信息,有效地从上下文文档中选择相关部分。我们首先提出多个强大的生成基线,使用基于变压器的编码器-解码器架构来合成答案。这些模型的性能等于或优于当前最先进的生成模型。接下来我们研究从上下文中选择相关信息。上下文选择器组件可以是摘要器、重新排序器、证据提取器或这些的组合。最后,我们有效地使用过滤后的上下文信息为生成模型提供最相关的线索,以合成事实上正确的自然语言答案。这显着提高了模型的性能。具有重新排序的上下文和证据的设置提供了最佳性能。我们还研究了不同训练策略对答案生成能力的影响。


























 京公网安备 11010802027423号
京公网安备 11010802027423号