Cognitive Computation ( IF 5.4 ) Pub Date : 2023-10-28 , DOI: 10.1007/s12559-023-10213-9 Pankayaraj Pathmanathan , Natalia Díaz-Rodríguez , Javier Del Ser
|
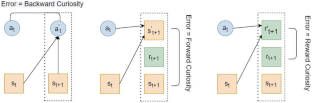
In this work, we investigate the means of using curiosity on replay buffers to improve offline multi-task continual reinforcement learning when tasks, which are defined by the non-stationarity in the environment, are non labeled and not evenly exposed to the learner in time. In particular, we investigate the use of curiosity both as a tool for task boundary detection and as a priority metric when it comes to retaining old transition tuples, which we respectively use to propose two different buffers. Firstly, we propose a Hybrid Reservoir Buffer with Task Separation (HRBTS), where curiosity is used to detect task boundaries that are not known due to the task-agnostic nature of the problem. Secondly, by using curiosity as a priority metric when it comes to retaining old transition tuples, a Hybrid Curious Buffer (HCB) is proposed. We ultimately show that these buffers, in conjunction with regular reinforcement learning algorithms, can be used to alleviate the catastrophic forgetting issue suffered by the state of the art on replay buffers when the agent’s exposure to tasks is not equal along time. We evaluate catastrophic forgetting and the efficiency of our proposed buffers against the latest works such as the Hybrid Reservoir Buffer (HRB) and the Multi-Time Scale Replay Buffer (MTR) in three different continual reinforcement learning settings. These settings are defined based on how many times the agent encounters the same task, how long they last, and how different new tasks are when compared to the old ones (i.e., how large the task drift is). The three settings are namely, 1. prolonged task encounter with substantial task drift, and no task re-visitation, 2. frequent, short-lived task encounter with substantial task drift and task re-visitation, and 3. every timestep task encounter with small task drift and task re-visitation. Experiments were done on classical control tasks and Metaworld environment. Experiments show that our proposed replay buffers display better immunity to catastrophic forgetting compared to existing works in all but the every time step task encounter with small task drift and task re-visitation. In this scenario curiosity will always be higher, thus not being an useful measure in both proposed buffers, making them not universally better than other approaches across all types of CL settings, and thereby opening up an avenue for further research.
中文翻译:
在持续离线强化学习中利用好奇心均匀地表示任务
在这项工作中,我们研究了当由环境中的非平稳性定义的任务没有标记并且没有及时均匀地暴露给学习者时,如何利用重放缓冲区的好奇心来改进离线 多任务持续强化学习。特别是,我们研究了好奇心的使用,既作为任务边界检测的工具,又作为保留旧转换元组的优先级度量,我们分别用它来提出两个不同的缓冲区。首先,我们提出了一种具有任务分离的混合存储缓冲区(HRBTS),其中好奇心用于检测由于问题的任务无关性质而未知的任务边界。其次,在保留旧的转换元组时,通过使用好奇心作为优先指标,提出了混合好奇缓冲区(HCB)。我们最终证明,当智能体接触到的任务随着时间的推移不相等时,这些缓冲区与常规强化学习算法相结合,可以用来缓解重播缓冲区的最新技术所遭受的灾难性遗忘问题。我们在三种不同的连续强化学习设置中,针对混合存储缓冲区(HRB)和多时间尺度重播缓冲区(MTR)等最新作品,评估了灾难性遗忘和我们提出的缓冲区的效率。这些设置是根据代理遇到相同任务的次数、持续时间以及新任务与旧任务相比的不同程度(即任务漂移有多大)来定义的。这三种设置是,1.长时间的任务遭遇,具有大量任务漂移,并且没有任务重新访问,2.频繁、短暂的任务遇到,具有大量任务漂移和任务重新访问,以及 3.每个时间步任务遇到小任务漂移和任务重访。在经典控制任务和Metaworld环境上进行了实验。实验表明,与现有的工作相比,我们提出的重放缓冲区表现出更好的抗灾难性遗忘能力,除了每次任务遇到小任务漂移和任务重访之外的情况。在这种情况下,好奇心总是会更高,因此在两个拟议的缓冲区中都不是一个有用的衡量标准,使得它们在所有类型的 CL 设置中并不普遍优于其他方法,从而为进一步研究开辟了途径。


























 京公网安备 11010802027423号
京公网安备 11010802027423号