Knowledge and Information Systems ( IF 2.7 ) Pub Date : 2023-10-30 , DOI: 10.1007/s10115-023-02003-4 Jixue Liu , Jiuyong Li , Lin Liu , Thuc Le , Feiyue Ye , Gefei Li
|
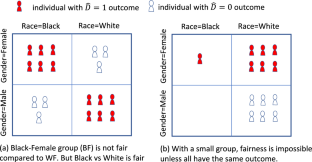
Predictive models such as decision trees and neural networks may produce predictions with unfairness. Some algorithms have been proposed to mitigate unfair predictions when protected attributes are considered individually. However, mitigating unfair predictions becomes more difficult when the application involves multiple protected attributes that are expected to be enforced simultaneously. This issue has not been solved, and existing methods are not able to solve it. The paper aims to be the first to solve this problem and proposes a method for post-processing unfair predictions to achieve fair ones. The method considers multiple simultaneous protected attributes together with context attributes, such as position, profession and education, that describe contextual details of the application. Our method consists of two steps. The first step uses a nonlinear optimization problem to determine the best adjustment plan for meeting the requirements of multiple simultaneous protected attributes while better preserving the original predictions. This optimization guarantees the solution to handle the interaction among multiple protected attributes regarding fairness in the best manner. The second steps learns adjustment thresholds using the results of optimization. The proposed method is evaluated using real-world datasets, and the evaluation shows that the proposed method makes effective adjustments to meet fairness requirements.
中文翻译:
Fairmod:在多个受保护的属性中做出公平的预测
决策树和神经网络等预测模型可能会产生不公平的预测。当单独考虑受保护的属性时,已经提出了一些算法来减轻不公平的预测。然而,当应用程序涉及多个预计同时执行的受保护属性时,减少不公平的预测就会变得更加困难。这个问题还没有得到解决,现有的方法也无法解决。本文旨在第一个解决这个问题,并提出了一种对不公平预测进行后处理以实现公平预测的方法。该方法考虑多个同时受保护的属性以及描述应用程序的上下文细节的上下文属性,例如职位、职业和教育。我们的方法包括两个步骤。第一步使用非线性优化问题来确定最佳调整方案,以满足多个同时受保护属性的要求,同时更好地保留原始预测。这种优化保证了解决方案能够以最佳方式处理多个受保护属性之间关于公平性的交互。第二步使用优化结果学习调整阈值。使用真实世界数据集对所提出的方法进行评估,评估表明所提出的方法进行了有效的调整以满足公平性要求。


























 京公网安备 11010802027423号
京公网安备 11010802027423号