Knowledge and Information Systems ( IF 2.7 ) Pub Date : 2023-11-29 , DOI: 10.1007/s10115-023-02013-2 Xiangfu Meng , Xiaoyan Zhang , Hongjin Huo , Qiangkui Leng
|
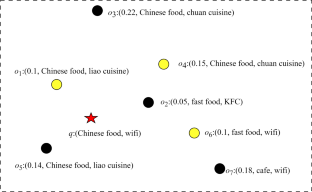
Spatial keyword query is a classical query processing mode for spatio-textual data, which aims to provide users the spatio-textual objects with the highest spatial proximity and textual similarity to the given query. However, the top-k result objects obtained by using the spatial keyword query mode are often similar to each other, while users hope that the system can pick top-k typicality results from the candidate query results in order to make users understand the representative features of the candidate result set. To deal with the problem of typicality analysis and typical object selection of spatio-textual data query results, a typicality evaluation and top-k approximate selection approach is proposed. First, the approach calculates the synthetic distances on dimensions of geographic location, textual semantics, and numeric attributes between all spatio-textual objects. And then, a hybrid index structure that can simultaneously support the location, text, and numeric multi-dimension matching is presented in order to expeditiously obtain the candidate query results. According to the synthetic distances between spatio-textual objects, a Gaussian kernel probability density estimation-based method for measuring the typicality of query results is proposed. To facilitate the query result analysis and top-k typical object selection, the Tournament strategy-based and local neighborhood-based top-k typical object approximate selection algorithms are presented, respectively. The experimental results demonstrated that the text semantic relevancy measuring method for spatio-textual objects is accurate and reasonable, and the local neighborhood-based top-k typicality result approximate selection algorithm achieved both the low error rate and high execution efficiency. The source code and datasets used in this paper are available to be accessed from https://github.com/JiaShengS/Typicality_analysis/.
中文翻译:
空间文本数据典型性查询结果的 Top-k 近似选择
空间关键词查询是一种经典的空间文本数据查询处理模式,旨在为用户提供与给定查询具有最高空间接近度和文本相似度的空间文本对象。然而,利用空间关键词查询方式得到的top- k个结果对象往往是相似的,而用户希望系统能够从候选查询结果中挑选出top- k个典型性结果,以便让用户了解其中的代表性特征候选结果集。针对时空数据查询结果的典型性分析和典型对象选择问题,提出了一种典型性评估和top- k近似选择方法。首先,该方法计算所有空间文本对象之间的地理位置、文本语义和数字属性维度的综合距离。然后,提出一种可以同时支持位置、文本和数字多维匹配的混合索引结构,以便快速获得候选查询结果。根据空间文本对象之间的合成距离,提出一种基于高斯核概率密度估计的查询结果典型性度量方法。为了便于查询结果分析和top- k典型对象选择,分别提出了基于锦标赛策略和基于局部邻域的top- k典型对象近似选择算法。实验结果表明,空间文本对象的文本语义相关性度量方法准确合理,基于局部邻域的top- k典型性结果近似选择算法实现了低错误率和高执行效率。本文使用的源代码和数据集可以从 https://github.com/JiaShengS/Typicality_analysis/ 访问。


























 京公网安备 11010802027423号
京公网安备 11010802027423号