Knowledge and Information Systems ( IF 2.7 ) Pub Date : 2023-12-01 , DOI: 10.1007/s10115-023-02010-5 Dipti Theng , Kishor K. Bhoyar
|
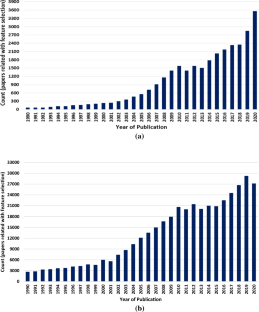
Learning algorithms can be less effective on datasets with an extensive feature space due to the presence of irrelevant and redundant features. Feature selection is a technique that effectively reduces the dimensionality of the feature space by eliminating irrelevant and redundant features without significantly affecting the quality of decision-making of the trained model. In the last few decades, numerous algorithms have been developed to identify the most significant features for specific learning tasks. Each algorithm has its advantages and disadvantages, and it is the responsibility of a data scientist to determine the suitability of a specific algorithm for a particular task. However, with the availability of a vast number of feature selection algorithms, selecting the appropriate one can be a daunting task for an expert. These challenges in feature selection have motivated us to analyze the properties of algorithms and dataset characteristics together. This paper presents significant efforts to review existing feature selection algorithms, providing an exhaustive analysis of their properties and relative performance. It also addresses the evolution, formulation, and usefulness of these algorithms. The manuscript further categorizes the algorithms analyzed in this review based on the properties required for a specific dataset and objective under study. Additionally, it discusses popular area-specific feature selection techniques. Finally, it identifies and discusses some open research challenges in feature selection that are yet to be overcome.
中文翻译:
机器学习的特征选择技术:二十多年研究综述
由于存在不相关和冗余的特征,学习算法对于具有广泛特征空间的数据集可能不太有效。特征选择是一种在不显着影响训练模型决策质量的情况下,通过消除不相关和冗余特征来有效降低特征空间维数的技术。在过去的几十年中,已经开发了许多算法来识别特定学习任务的最重要特征。每种算法都有其优点和缺点,数据科学家有责任确定特定算法对特定任务的适用性。然而,随着大量特征选择算法的出现,选择合适的算法对于专家来说可能是一项艰巨的任务。特征选择中的这些挑战促使我们一起分析算法的属性和数据集特征。本文提出了回顾现有特征选择算法的重大努力,对其属性和相对性能进行了详尽的分析。它还讨论了这些算法的演变、公式化和实用性。该手稿根据特定数据集和所研究目标所需的属性进一步对本次评论中分析的算法进行分类。此外,它还讨论了流行的特定区域特征选择技术。最后,它确定并讨论了特征选择中尚未克服的一些开放研究挑战。


























 京公网安备 11010802027423号
京公网安备 11010802027423号