Cognitive Computation ( IF 5.4 ) Pub Date : 2023-12-07 , DOI: 10.1007/s12559-023-10226-4 Zhenghongyuan Ni , Ye Jin , Peng Liu , Wei Zhao
|
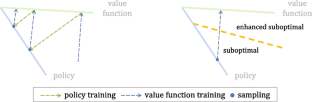
In realistic sparse reward tasks, existing theoretical methods cannot be effectively applied due to the low sampling probability ofrewarded episodes. Profound research on methods based on intrinsic rewards has been conducted to address this issue, but exploration with sparse rewards remains a great challenge. This paper describes the loop enhancement effect in exploration processes with sparse rewards. After each fully trained iteration, the execution probability of ineffective actions is higher than thatof other suboptimal actions, which violates biological habitual behavior principles and is not conducive to effective training. This paper proposes corresponding theorems of relieving the loop enhancement effect in the exploration process with sparse rewards and a heuristic exploration method based on action effectiveness constraints (AEC), which improves policy training efficiency by relieving the loop enhancement effect. Inspired by the fact that animals form habitual behaviors and goal-directed behaviors through the dorsolateral striatum and dorsomedial striatum. The function of the dorsolateral striatum is simulated by an action effectiveness evaluation mechanism (A2EM), which aims to reduce the rate of ineffective samples and improve episode reward expectations. The function of the dorsomedial striatum is simulated by an agent policy network, which aims to achieve task goals. The iterative training of A2EM and the policy forms the AEC model structure. A2EM provides effective samples for the agent policy; the agent policy provides training constraints for A2EM. The experimental results show that A2EM can relieve the loop enhancement effect and has good interpretability and generalizability. AEC enables agents to effectively reduce the loop rate in samples, can collect more effective samples, and improve the efficiency of policy training. The performance of AEC demonstrates the effectiveness of a biological heuristic approach that simulates the function of the dorsal striatum. This approach can be used to improve the robustness of agent exploration with sparse rewards.
中文翻译:
一种基于动作有效性约束的新颖启发式探索方法,缓解稀疏奖励强化学习中的循环增强效应
在现实的稀疏奖励任务中,由于奖励事件的采样概率较低,现有的理论方法无法有效应用。为了解决这个问题,人们对基于内在奖励的方法进行了深入的研究,但稀疏奖励的探索仍然是一个巨大的挑战。本文描述了稀疏奖励探索过程中的循环增强效应。每次经过充分训练的迭代后,无效动作的执行概率高于其他次优动作的执行概率,这违反了生物习惯行为原则,不利于有效训练。本文提出了缓解稀疏奖励探索过程中循环增强效应的相应定理以及基于动作有效性约束(AEC)的启发式探索方法,通过缓解循环增强效应来提高策略训练效率。受到动物通过背外侧纹状体和背内侧纹状体形成习惯行为和目标导向行为这一事实的启发。背外侧纹状体的功能通过动作有效性评估机制(A2EM)进行模拟,旨在降低无效样本率并提高事件奖励预期。背内侧纹状体的功能由代理策略网络模拟,旨在实现任务目标。A2EM和策略的迭代训练形成了AEC模型结构。A2EM为代理政策提供有效样本;代理策略为 A2EM 提供了训练约束。实验结果表明,A2EM可以缓解循环增强效应,具有良好的可解释性和泛化性。AEC使智能体能够有效降低样本的循环率,能够收集到更多的有效样本,提高策略训练的效率。AEC 的性能证明了模拟背侧纹状体功能的生物启发式方法的有效性。这种方法可用于提高具有稀疏奖励的代理探索的鲁棒性。


























 京公网安备 11010802027423号
京公网安备 11010802027423号