Circuits, Systems, and Signal Processing ( IF 2.3 ) Pub Date : 2023-12-24 , DOI: 10.1007/s00034-023-02570-5 Bachchu Paul , Santanu Phadikar
|
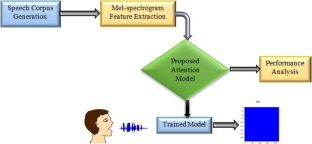
People are curious about voice commands for the next generation of interaction. It will play a dominant role in communicating with smart devices in the future. However, language remains a significant barrier to the widespread use of these devices. Even the existing models for the traditional languages need to compute extensive parameters, resulting in higher computational costs. The most inconvenient in the latest advanced models is that they are unable to function on devices with constrained resources. This paper proposes a novel end-to-end speech recognition based on a low-cost Bidirectional Long Short Term Memory (BiLSTM) attention model. The mel-spectrogram of the speech signals has been generated to feed into the proposed neural attention model to classify isolated words. It consists of three convolution layers followed by two layers of BiLSTM that encode a vector of length 64 to get attention against the input sequence. The convolution layers characterize the relationship among the energy bins in the spectrogram. The BiLSTM network removes the prolonged reliance on the input sequence, and the attention block finds the most significant region in the input sequence, reducing the computational cost in the classification process. The encoded vector by the attention head is fed to three-layered fully connected networks for recognition. The model takes only 133K parameters, less than several current state-of-the-art models for isolated word recognition. Two datasets, the Speech Command Dataset (SCD), and a self-made dataset we developed for fifteen spoken colors in the Bengali dialect, are utilized in this study. Applying the proposed technique, the performance evaluation with validation and test accuracy in the Bengali color dataset reaches 98.82% and 98.95%, respectively, which outperforms the current state-of-the-art models regarding accuracy and model size. When the SCD has been trained using the same network model, the average test accuracy obtained is 96.95%. To underpin the proposed model, the outcome is compared with the recent state-of-the-art models, and the result shows the superiority of the proposed model.
中文翻译:
RAttSR:一种新颖的低成本重构的基于注意力的端到端语音识别器
人们对下一代交互的语音命令感到好奇。它将在未来与智能设备的通信中发挥主导作用。然而,语言仍然是这些设备广泛使用的重大障碍。即使是传统语言的现有模型也需要计算大量参数,从而导致更高的计算成本。最新的高级模型最不方便的是它们无法在资源有限的设备上运行。本文提出了一种基于低成本双向长短期记忆(BiLSTM)注意力模型的新型端到端语音识别。已生成语音信号的梅尔谱图,将其输入到所提出的神经注意模型中,以对孤立词进行分类。它由三个卷积层组成,后跟两层 BiLSTM,对长度为 64 的向量进行编码,以引起对输入序列的关注。卷积层表征了频谱图中能量仓之间的关系。BiLSTM网络消除了对输入序列的长期依赖,注意力块找到输入序列中最重要的区域,减少了分类过程中的计算成本。注意力头编码的向量被馈送到三层全连接网络进行识别。该模型仅需要 133K 个参数,少于当前几个最先进的孤立词识别模型。本研究使用了两个数据集,即语音命令数据集 (SCD) 和我们为孟加拉语方言中的 15 种口语颜色开发的自制数据集。应用所提出的技术,在孟加拉颜色数据集中验证和测试准确度的性能评估分别达到 98.82% 和 98.95%,在准确度和模型大小方面优于当前最先进的模型。当使用相同的网络模型训练SCD时,获得的平均测试准确率为96.95%。为了支持所提出的模型,将结果与最近最先进的模型进行了比较,结果表明了所提出模型的优越性。


























 京公网安备 11010802027423号
京公网安备 11010802027423号