Knowledge and Information Systems ( IF 2.7 ) Pub Date : 2023-12-28 , DOI: 10.1007/s10115-023-02006-1 Mingjie Wang , Siyuan Wang , Jianxiong Guo , Weijia Jia
|
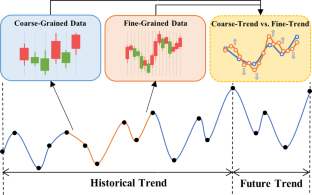
Stock trend prediction (STP) aims to predict price fluctuation, which is critical in financial trading. The existing STP approaches only use market data with the same granularity (e.g., as daily market data). However, in the actual financial investment, there are a large number of more detailed investment signals contained in finer-grained data (e.g., high-frequency data). This motivates us to research how to leverage multi-granularity market data to capture more useful information and improve the accuracy in the task of STP. However, the effective utilization of multi-granularity data presents a major challenge. Firstly, the iteration of multi-granularity data with time will lead to more complex noise, which is difficult to extract signals. Secondly, the difference in granularity may lead to opposite target trends in the same time interval. Thirdly, the target trends of stocks with similar features can be quite different, and different sizes of granularity will aggravate this gap. In order to address these challenges, we present a self-supervised framework of multi-granularity denoising contrastive learning (MDC). Specifically, we construct a dynamic dictionary of memory, which can obtain clear and unified representations by filtering noise and aligning multi-granularity data. Moreover, we design two contrast learning modules during the fine-tuning stage to solve the differences in trends by constructing additional self-supervised signals. Besides, in the pre-training stage, we design the granularity domain adaptation module (GDA) to address the issues of temporal inconsistency and data imbalance associated with different granularity in financial data, alongside the memory self-distillation module (MSD) to tackle the challenge posed by a low signal-to-noise ratio. The GDA alleviates these complications by replacing a portion of the coarse-grained data with the preceding time step’s fine-grained data, while the MSD seeks to filter out intrinsic noise by aligning the fine-grained representations with the coarse-grained representations’ distribution using a self-distillation mechanism. Extensive experiments on the CSI 300 and CSI 100 datasets show that our framework stands out from the existing top-level systems and has excellent profitability in real investing scenarios.
中文翻译:
通过预训练多粒度去噪对比学习改进股票趋势预测
股票趋势预测(STP)旨在预测价格波动,这在金融交易中至关重要。现有的STP方法仅使用具有相同粒度的市场数据(例如,每日市场数据)。然而,在实际的金融投资中,更细粒度的数据(例如高频数据)中蕴藏着大量更详细的投资信号。这促使我们研究如何利用多粒度的市场数据来捕获更多有用的信息并提高STP任务的准确性。然而,多粒度数据的有效利用提出了重大挑战。首先,多粒度数据随时间的迭代会导致更加复杂的噪声,难以提取信号。其次,粒度的差异可能会导致同一时间间隔内目标趋势相反。第三,具有相似特征的股票的目标走势可能存在较大差异,而粒度大小的不同会加剧这种差距。为了应对这些挑战,我们提出了一个多粒度去噪对比学习(MDC)的自监督框架。具体来说,我们构建了一个动态的内存字典,它可以通过过滤噪声和对齐多粒度数据来获得清晰统一的表示。此外,我们在微调阶段设计了两个对比学习模块,通过构造额外的自监督信号来解决趋势的差异。此外,在预训练阶段,我们设计了粒度域适应模块(GDA)来解决金融数据中不同粒度的时间不一致和数据不平衡问题,同时设计了内存自蒸馏模块(MSD)来解决金融数据中不同粒度的时间不一致和数据不平衡问题。低信噪比带来的挑战。GDA 通过用前一时间步的细粒度数据替换一部分粗粒度数据来减轻这些复杂性,而 MSD 则通过使用以下方法将细粒度表示与粗粒度表示的分布对齐来过滤掉内在噪声:自蒸馏机制。在沪深300和沪深100数据集上的大量实验表明,我们的框架在现有的顶级系统中脱颖而出,并且在真实投资场景中具有出色的盈利能力。


























 京公网安备 11010802027423号
京公网安备 11010802027423号