Language Resources and Evaluation ( IF 2.7 ) Pub Date : 2024-01-02 , DOI: 10.1007/s10579-023-09716-6 Soran Badawi , Arefeh Kazemi , Vali Rezaie
|
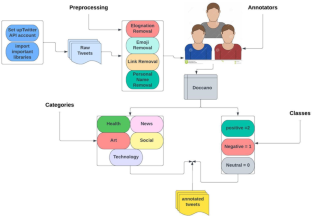
Language is essential for communication and the expression of feelings and sentiments. As technology advances, language has become increasingly ubiquitous in our lives. One of the most critical research areas in natural language processing (NLP) is sentiment analysis, which aims to identify and extract opinions and attitudes from text. Sentiment analysis is particularly useful for understanding public opinion on products, services, and topics of interest. While sentiment analysis systems are well-developed for English, this differs for other languages, such as Kurdish. This is because less-resourced languages have fewer NLP resources, including annotated datasets. To bridge this gap, this paper introduces KurdiSent, the first manually annotated dataset for Kurdish sentiment analysis. KurdiSent consists of over 12,000 instances labeled as positive, negative, or neutral. The corpus covers the Sorani dialect of Kurdish, the most widely spoken dialect. To ensure the quality of KurdiSent, the dataset was trained on machine learning and deep learning classifiers. The experimental results indicated that XLM-R outperformed all machine learning and deep learning classifiers, with an accuracy of 85%, compared to 81% for the best machine learning classifier. KurdiSent is a valuable resource for the NLP community, as it will enable researchers to develop and improve sentiment analysis systems for Kurdish. The corpus will facilitate a better understanding of public opinion in Kurdish-speaking communities.
中文翻译:
KurdiSent:库尔德情绪分析语料库
语言对于沟通和表达感情和情绪至关重要。随着技术的进步,语言在我们的生活中变得越来越普遍。自然语言处理(NLP)最关键的研究领域之一是情感分析,旨在从文本中识别和提取观点和态度。情绪分析对于了解公众对产品、服务和感兴趣主题的看法特别有用。虽然英语的情绪分析系统很完善,但对于库尔德语等其他语言来说却有所不同。这是因为资源较少的语言拥有较少的 NLP 资源,包括带注释的数据集。为了弥补这一差距,本文引入了 KurdiSent,这是第一个用于库尔德情绪分析的手动注释数据集。KurdiSent 包含超过 12,000 个标记为正面、负面或中立的实例。该语料库涵盖库尔德语索拉尼方言,这是使用最广泛的方言。为了确保 KurdiSent 的质量,数据集接受了机器学习和深度学习分类器的训练。实验结果表明,XLM-R 的性能优于所有机器学习和深度学习分类器,准确率为 85%,而最佳机器学习分类器的准确率为 81%。KurdiSent 是 NLP 社区的宝贵资源,因为它将使研究人员能够开发和改进库尔德语情绪分析系统。该语料库将有助于更好地了解库尔德语社区的民意。


























 京公网安备 11010802027423号
京公网安备 11010802027423号