Language Resources and Evaluation ( IF 2.7 ) Pub Date : 2024-01-13 , DOI: 10.1007/s10579-023-09708-6 Kiran Babu Nelatoori , Hima Bindu Kommanti
|
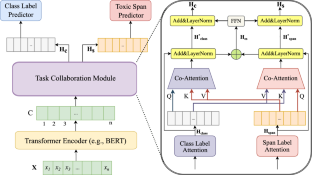
Detecting toxic comments and rationale for the offensiveness of a social media post promotes moderation of social media content. For this purpose, we propose a Co-Attentive Multi-task Learning (CA-MTL) model through transfer learning for low-resource Hindi-English (commonly known as Hinglish) toxic texts. Together, the cooperative tasks of rationale/span detection and toxic comment classification create a strong multi-task learning objective. A task collaboration module is designed to leverage the bi-directional attention between the classification and span prediction tasks. The combined loss function of the model is constructed using the individual loss functions of these two tasks. Although an English toxic span detection dataset exists, one for Hinglish code-mixed text does not exist as of today. Hence, we developed a dataset with toxic span annotations for Hinglish code-mixed text. The proposed CA-MTL model is compared against single-task and multi-task learning models that lack the co-attention mechanism, using multilingual and Hinglish BERT variants. The F1 scores of the proposed CA-MTL model with HingRoBERTa encoder for both tasks are significantly higher than the baseline models. Caution: This paper may contain words disturbing to some readers.
中文翻译:
利用共同注意多任务学习在代码混合文本中进行有毒评论分类和基本原理提取
检测有毒评论和社交媒体帖子的攻击性理由可以促进社交媒体内容的审核。为此,我们通过针对低资源印地语-英语(俗称印度英语)有毒文本的迁移学习,提出了一种共同关注多任务学习(CA-MTL)模型。基本原理/跨度检测和有毒评论分类的协作任务共同创建了强大的多任务学习目标。任务协作模块旨在利用分类和跨度预测任务之间的双向注意力。该模型的组合损失函数是使用这两个任务的单独损失函数构建的。尽管存在英语有毒跨度检测数据集,但截至目前还不存在印度英语代码混合文本的数据集。因此,我们为印度英语代码混合文本开发了一个带有有毒跨度注释的数据集。使用多语言和印度英语 BERT 变体,将所提出的 CA-MTL 模型与缺乏共同注意机制的单任务和多任务学习模型进行比较。所提出的带有 HingRoBERTa 编码器的 CA-MTL 模型对于这两项任务的 F1 分数均显着高于基线模型。注意:本文可能包含一些令某些读者感到不安的词语。


























 京公网安备 11010802027423号
京公网安备 11010802027423号