Theoretical and Applied Climatology ( IF 3.4 ) Pub Date : 2024-02-10 , DOI: 10.1007/s00704-024-04862-5 Paramjeet Singh Tulla , Pravendra Kumar , Dinesh Kumar Vishwakarma , Rohitashw Kumar , Alban Kuriqi , Nand Lal Kushwaha , Jitendra Rajput , Aman Srivastava , Quoc Bao Pham , Kanhu Charan Panda , Ozgur Kisi
|
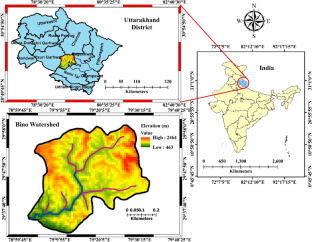
Water erosion creates adverse impacts on agricultural production, infrastructure, and water quality across the world, especially in hilly areas. Regional-scale water erosion assessment is essential, but existing models could have been more efficient in predicting the suspended sediment load. Further, data scarcity is a common problem in predicting sediment load. Thus, the current study aimed at modeling the suspended sediment yield of a hilly watershed (i.e., Bino watershed, Uttarakhand-India) using machine learning (ML) algorithms for a data-scarce situation. For this purpose, the ML models, viz., adaptive neuro-fuzzy inference system (ANFIS) and fuzzy logic (FL) were developed using data from ten years (2000–2009) only. Further, runoff and suspended sediment concentration (SSC) were obtained as the primary influencing factors. Varying combinations of lagged SSC and runoff data were considered as model inputs. The ANFIS and FL models were compared with the conventional multiple linear regression (MLR) model. Results indicated that the ANFIS model performed better than the FL and MLR models. Thus, it was concluded that the ANFIS model could be used as a benchmark for sediment yield prediction in hilly terrain in data-scarce situations. The research work would help field investigators in selecting the proper tool for estimating suspended sediment yield/load and policymakers to make appropriate decisions to reduce the devastating impact of soil erosion in hilly terrains.
中文翻译:
在数据稀缺的情况下使用软计算算法估算丘陵流域的每日悬浮泥沙产量:北阿坎德邦比诺流域的案例研究
水土流失对世界各地的农业生产、基础设施和水质造成不利影响,特别是在丘陵地区。区域规模的水侵蚀评估至关重要,但现有模型在预测悬浮泥沙负荷方面可能更有效。此外,数据缺乏是预测沉积物负荷的一个常见问题。因此,当前的研究旨在针对数据稀缺的情况,使用机器学习 (ML) 算法对丘陵流域(即印度北阿坎德邦的比诺流域)的悬浮沉积物产量进行建模。为此,仅使用十年(2000-2009)的数据开发了机器学习模型,即自适应神经模糊推理系统(ANFIS)和模糊逻辑(FL)。此外,径流和悬浮泥沙浓度(SSC)被作为主要影响因素。滞后的SSC 和径流数据的不同组合被视为模型输入。将 ANFIS 和 FL 模型与传统的多元线性回归 (MLR) 模型进行比较。结果表明,ANFIS 模型的性能优于 FL 和 MLR 模型。因此,得出的结论是,ANFIS模型可以作为数据稀缺情况下丘陵地形产沙量预测的基准。这项研究工作将帮助实地调查人员选择适当的工具来估计悬浮沉积物产量/负荷,并帮助政策制定者做出适当的决定,以减少丘陵地区土壤侵蚀的破坏性影响。


























 京公网安备 11010802027423号
京公网安备 11010802027423号