Signal, Image and Video Processing ( IF 2.3 ) Pub Date : 2024-02-10 , DOI: 10.1007/s11760-024-02996-7 Souvik Maiti , Debasis Maji , Ashis Kumar Dhara , Gautam Sarkar
|
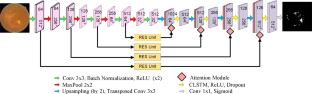
Diabetic retinopathy, an eye complication that causes retinal damage, can impair the vision and even result in blindness, if not treated on time. Regular eye screening is essential for patients with diabetics because diabetic retinopathy advances significantly without symptoms. Exudates are a primary symptom of diabetic retinopathy, and their automatic recognition can help in early diagnosis. The convolution operation which concentrates mostly on extracting the local features provides less emphasis on global information resulting the long-range dependencies to be addressed while traversing through multiple layers. The proposed segmentation model utilizes both the channel and spatial attention mechanisms to effectively establish the long-range dependencies at various levels of feature extraction. The proposed methodology also utilizes the convolutional long- and short-term memory algorithm during the propagation from input-to-state and from the state-to-state to take into account the spatiotemporal dependencies and the residual extended skip block for widening the network's receptive zone. Implementing the potentials of neural networks, this study excels at identifying complex patterns and minute features in retinal images. The effectiveness of the proposed method has been verified by conducting experiments on various retinal image datasets, such as IDRiD, MESSIDOR, DIARETDB0, and DIARETDB1, which clearly indicates the superiority of this method over other existing methods across a wide range of evaluation metrics, namely specificity, F1-score, accuracy, sensitivity, and intersection-over-union. Additionally, the model's ability to achieve an overall accuracy of 97.7% makes it a viable application that can provide clinicians important insights into the diagnosis and treatment of diabetic retinopathy.
中文翻译:
具有 CLSTM 和 RES 单元的注意力丰富的编码器-解码器架构,用于分割视网膜图像中的渗出物
糖尿病视网膜病变是一种导致视网膜损伤的眼部并发症,如果不及时治疗,可能会损害视力,甚至导致失明。定期眼部筛查对于糖尿病患者至关重要,因为糖尿病视网膜病变在没有症状的情况下会显着进展。渗出物是糖尿病视网膜病变的主要症状,其自动识别有助于早期诊断。卷积运算主要集中于提取局部特征,不太重视全局信息,从而导致在遍历多层时解决远程依赖性。所提出的分割模型利用通道和空间注意机制来有效地建立各个特征提取级别的远程依赖性。所提出的方法还在从输入到状态和从状态到状态的传播过程中利用卷积长短期记忆算法来考虑时空依赖性和残余扩展跳跃块,以扩大网络的接受范围区。这项研究发挥了神经网络的潜力,擅长识别视网膜图像中的复杂模式和微小特征。通过在各种视网膜图像数据集(例如IDRiD、MESSIDOR、DIARETDB0和DIARETDB1)上进行实验验证了所提出方法的有效性,这清楚地表明该方法在广泛的评估指标上相对于其他现有方法的优越性,即特异性、F1 分数、准确性、灵敏度和交集。此外,该模型能够实现 97.7% 的总体准确率,使其成为一种可行的应用,可以为临床医生提供有关糖尿病视网膜病变诊断和治疗的重要见解。


























 京公网安备 11010802027423号
京公网安备 11010802027423号