International Journal of Environmental Science and Technology ( IF 3.1 ) Pub Date : 2024-02-10 , DOI: 10.1007/s13762-023-05452-0 M. Dassamiour , D. Samai , N. Faghmous , R. Boustila
|
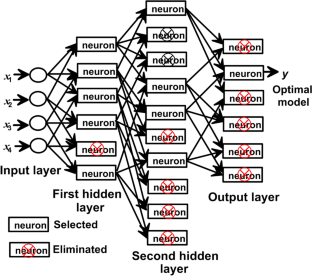
Marine sedimentary phosphate rock is the primary source for manufacturing phosphate fertilizers. It is composed mainly of phosphorus and other elements. Some of these elements, including heavy metals, occur as trace elements. Notably, arsenic, classified as a Group I human carcinogen, is among them. This research aims to develop an explicit model equation for predicting the concentration of arsenic in phosphate rock using backward stepwise multiple regression and two-group method of data handling algorithms: the combinatorial and type neural networks. A database of 277 datasets was compiled from thirteen reputable references for this purpose. The models’ input data are the major oxide contents (P2O5, CaO, MgO, SiO2, Al2O3, Fe2O3, K2O, and Na2O) in the phosphate samples. Three models of multiple regression and twenty-one models were constructed by combining various parameters, like the transformation function of input data and the neuron activation function. The performance of the proposed models was evaluated using metrics such as root mean square error, mean absolute error, and the coefficient of determination. In addition, sensitivity analysis was performed to inspect the impact of input variables on the model output. The results showed that the combinatorial algorithm provides the best model for predicting arsenic concentration with the highest level of accuracy in prediction. The validation results suggest that the combinatorial algorithm can be considered a promising approach for predicting heavy metal concentrations in phosphate rock with improved accuracy, and the model’s explicit form makes its practical application highly feasible.
中文翻译:
基于数据处理的沉积磷矿砷浓度预测模型的多元回归和分组方法
海洋沉积磷矿是制造磷肥的主要来源。主要由磷和其他元素组成。其中一些元素,包括重金属,以微量元素的形式存在。值得注意的是,砷被列为第一类人类致癌物。本研究旨在开发一个显式模型方程,使用向后逐步多元回归和数据处理算法的两组方法:组合和类型神经网络来预测磷矿中砷的浓度。为此目的,根据 13 个信誉良好的参考文献编制了包含 277 个数据集的数据库。模型的输入数据是磷酸盐样品中的主要氧化物含量(P 2 O 5、CaO、MgO、SiO 2、Al 2 O 3、Fe 2 O 3、K 2 O 和Na 2 O)。通过组合输入数据的变换函数和神经元激活函数等各种参数,构建了三个多元回归模型和二十一个模型。使用均方根误差、平均绝对误差和确定系数等指标评估所提出模型的性能。此外,还进行了敏感性分析,以检查输入变量对模型输出的影响。结果表明,组合算法提供了预测砷浓度的最佳模型,预测精度最高。验证结果表明,组合算法可以被认为是预测磷矿中重金属浓度的一种有前途的方法,且精度更高,并且该模型的显式形式使其实际应用具有高度可行性。


























 京公网安备 11010802027423号
京公网安备 11010802027423号