Journal of Real-Time Image Processing ( IF 3 ) Pub Date : 2024-02-16 , DOI: 10.1007/s11554-024-01413-z Huilin Wang , Huaming Qian , Shuai Feng , Wenna Wang
|
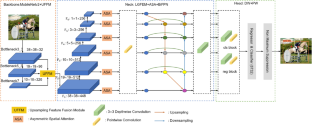
The current target detection algorithm based on deep learning has many redundant convolution calculations, which are difficult to apply to low-energy mobile devices, such as intelligent inspection robots and automatic driving. To solve this problem, we propose a lightweight target detection algorithm, L-SSD, based on depth-separable convolution. First, we chose the lightweight network MobileNetv2 as the backbone feature extraction network, and we proposed an upsampling feature fusion module (UFFM) to fuse the output feature maps of MobileNetv2. Deep semantic information is introduced into the shallow feature map to improve the feature extraction capability while reducing the complexity of the model. Second, we propose a local–global feature extraction module (LGFEM), which uses LGFEM to generate five additional feature layers to expand the feature map’s receptive field and improve the model’s detection accuracy. Then, we use an improved weighted bidirectional feature pyramid (BiFPN) for feature fusion to construct a new feature pyramid that fully utilizes the feature information between different layers. Finally, we propose asymmetric spatial attention (ASA) that enhances the expression ability of the features before BiFPN feature fusion, providing good positional information for the feature pyramid. Experimental results on the PASCAL VOC and MS COCO datasets show that the model parameters and model complexity of L-SSD are reduced by 85.9% and 96.1%, respectively, compared to SSD. A detection speed of 106 frames per second was achieved in NVIDIA GeForce RTX 3060 with detection accuracies of 73.8% and 22.4%, respectively. The optimal balance of model parameters, model complexity, detection accuracy, and speed are achieved.
中文翻译:
L-SSD:基于深度可分离卷积的轻量级SSD目标检测
目前基于深度学习的目标检测算法存在大量冗余卷积计算,难以应用于智能巡检机器人、自动驾驶等低能耗移动设备。为了解决这个问题,我们提出了一种基于深度可分离卷积的轻量级目标检测算法L-SSD。首先,我们选择轻量级网络MobileNetv2作为主干特征提取网络,并提出了一个上采样特征融合模块(UFFM)来融合MobileNetv2的输出特征图。将深层语义信息引入浅层特征图中,提高特征提取能力,同时降低模型复杂度。其次,我们提出了一个局部-全局特征提取模块(LGFEM),它使用LGFEM生成五个附加特征层,以扩大特征图的感受野并提高模型的检测精度。然后,我们使用改进的加权双向特征金字塔(BiFPN)进行特征融合,构建一个充分利用不同层之间特征信息的新特征金字塔。最后,我们提出了非对称空间注意力(ASA),增强了BiFPN特征融合之前特征的表达能力,为特征金字塔提供了良好的位置信息。在PASCAL VOC和MS COCO数据集上的实验结果表明,与SSD相比,L-SSD的模型参数和模型复杂度分别降低了85.9%和96.1%。 NVIDIA GeForce RTX 3060 的检测速度达到每秒 106 帧,检测准确率分别为 73.8% 和 22.4%。实现了模型参数、模型复杂度、检测精度、速度的最佳平衡。


























 京公网安备 11010802027423号
京公网安备 11010802027423号