International Journal of Computer Vision ( IF 19.5 ) Pub Date : 2024-02-19 , DOI: 10.1007/s11263-024-02002-0 Yufan Liu , Jiajiong Cao , Bing Li , Weiming Hu , Jingting Ding , Liang Li , Stephen Maybank
|
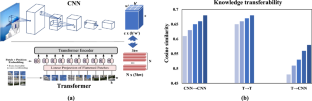
The Transformer network architecture has gained attention due to its ability to learn global relations and its superior performance. To boost performance, it is natural to distill complementary knowledge from a Transformer network to a convolutional neural network (CNN). However, most existing knowledge distillation methods only consider homologous-architecture distillation, which may not be suitable for cross-architecture scenarios, such as from Transformer to CNN. To address this problem, we analyze the globality and transferability of models, which reflect the ability to capture global knowledge and transfer knowledge from teacher to student, respectively. Inspired by our observations, a novel cross-architecture knowledge distillation method is proposed, which supports bi-directional distillation including from Transformer to CNN and from CNN to Transformer. Specifically, rather than directly mimicking the output and intermediate features of the teacher, a partial cross-attention projector (PCA/iPCA) and a group-wise linear projector (GL/iGL) are introduced to align the student features with the teacher’s in two projected feature spaces. To better match the teacher’s knowledge with the student’s knowledge, an adaptive distillation router (ADR) is presented to decide the knowledge from which layer the teacher should be distilled to guide which layer of the student. A multi-view robust training scheme is further presented, to improve the robustness of the framework for distillation. Extensive experiments show that the proposed method outperforms 17 state-of-the-art methods on both small-scale and large-scale datasets.
中文翻译:
跨架构知识蒸馏
Transformer网络架构因其学习全局关系的能力和优越的性能而受到关注。为了提高性能,从 Transformer 网络中提取互补知识到卷积神经网络 (CNN) 是很自然的事情。然而,大多数现有的知识蒸馏方法只考虑同源架构蒸馏,这可能不适合跨架构场景,例如从 Transformer 到 CNN。为了解决这个问题,我们分析了模型的全局性和可迁移性,它们分别反映了捕获全局知识和将知识从教师转移到学生的能力。受我们观察的启发,提出了一种新颖的跨架构知识蒸馏方法,该方法支持双向蒸馏,包括从 Transformer 到 CNN 以及从 CNN 到 Transformer。具体来说,不是直接模仿教师的输出和中间特征,而是引入部分交叉注意投影仪(PCA / iPCA)和分组线性投影仪(GL / iGL)来将学生特征与教师的特征分为两个部分:投影特征空间。为了更好地匹配教师的知识和学生的知识,提出了自适应蒸馏路由器(ADR)来决定教师应该从哪一层知识中蒸馏出来以指导学生的哪一层。进一步提出了多视图鲁棒训练方案,以提高蒸馏框架的鲁棒性。大量实验表明,所提出的方法在小规模和大规模数据集上均优于 17 种最先进的方法。


























 京公网安备 11010802027423号
京公网安备 11010802027423号