当前位置:
X-MOL 学术
›
CIRP Ann. Manuf. Technol.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Tolerance Information Extraction for Mechanical Engineering Drawings – A Digital Image Processing and Deep Learning-based Model
CIRP Journal of Manufacturing Science and Technology ( IF 4.8 ) Pub Date : 2024-02-20 , DOI: 10.1016/j.cirpj.2024.01.013 Yuanping Xu , Chaolong Zhang , Zhijie Xu , Chao Kong , Dan Tang , Xin Deng , Tukun Li , Jin Jin
CIRP Journal of Manufacturing Science and Technology ( IF 4.8 ) Pub Date : 2024-02-20 , DOI: 10.1016/j.cirpj.2024.01.013 Yuanping Xu , Chaolong Zhang , Zhijie Xu , Chao Kong , Dan Tang , Xin Deng , Tukun Li , Jin Jin
|
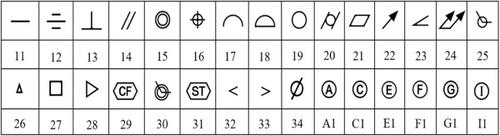
Mechanical engineering drawings (MEDs) accompany a product lifecycle from conceptional design to final production. The digitisation of MEDs has become increasingly important due to demands for data authenticity, intellectual property protection, efficient data storage and communication, and compliance with data integrity and security regulations. Unlike CAD-based engineering design software, legacy MEDs are often manually drawn or contain manually labeled specifications on blueprints. A notable gap exists in the automated process pipeline of modern Computer-Aided Tolerance (CAT) software, particularly in integrating Geometrical Tolerance Specification Callouts (GTSC) on MEDs. This study proposes an integrated model based on digital image processing and deep learning, which combines character (symbol, text and number) localization, segmentation, and recognition to intelligently identify and read GTSCs on MEDs. The focus of this work is on image filtering, GTSC block localization and tilt correction, multiple lines and character segmentation, and semantic recognition. Experiment results demonstrate that this innovative technique effectively automates the labor-intensive process of reading and registering GTSC with a precision performance that meets industry benchmarks.
中文翻译:

机械工程图纸的公差信息提取——基于数字图像处理和深度学习的模型
机械工程图纸 (MED) 伴随着从概念设计到最终生产的产品生命周期。由于对数据真实性、知识产权保护、高效数据存储和通信以及遵守数据完整性和安全法规的要求,MED 的数字化变得越来越重要。与基于 CAD 的工程设计软件不同,传统 MED 通常是手动绘制的或在蓝图上包含手动标记的规格。现代计算机辅助公差 (CAT) 软件的自动化流程管道中存在显着差距,特别是在 MED 上集成几何公差规范标注 (GTSC) 方面。本研究提出了一种基于数字图像处理和深度学习的集成模型,结合字符(符号、文本和数字)定位、分割和识别,智能识别和读取 MED 上的 GTSC。这项工作的重点是图像滤波、GTSC 块定位和倾斜校正、多行和字符分割以及语义识别。实验结果表明,这种创新技术有效地自动化了读取和注册 GTSC 的劳动密集型过程,其精度性能符合行业基准。
更新日期:2024-02-20
中文翻译:
机械工程图纸的公差信息提取——基于数字图像处理和深度学习的模型
机械工程图纸 (MED) 伴随着从概念设计到最终生产的产品生命周期。由于对数据真实性、知识产权保护、高效数据存储和通信以及遵守数据完整性和安全法规的要求,MED 的数字化变得越来越重要。与基于 CAD 的工程设计软件不同,传统 MED 通常是手动绘制的或在蓝图上包含手动标记的规格。现代计算机辅助公差 (CAT) 软件的自动化流程管道中存在显着差距,特别是在 MED 上集成几何公差规范标注 (GTSC) 方面。本研究提出了一种基于数字图像处理和深度学习的集成模型,结合字符(符号、文本和数字)定位、分割和识别,智能识别和读取 MED 上的 GTSC。这项工作的重点是图像滤波、GTSC 块定位和倾斜校正、多行和字符分割以及语义识别。实验结果表明,这种创新技术有效地自动化了读取和注册 GTSC 的劳动密集型过程,其精度性能符合行业基准。


























 京公网安备 11010802027423号
京公网安备 11010802027423号