International Journal of Computer Vision ( IF 19.5 ) Pub Date : 2024-02-26 , DOI: 10.1007/s11263-024-01988-x Weixiang Hong , Wang Ren , Jiangwei Lao , Lele Xie , Liheng Zhong , Jian Wang , Jingdong Chen , Honghai Liu , Wei Chu
|
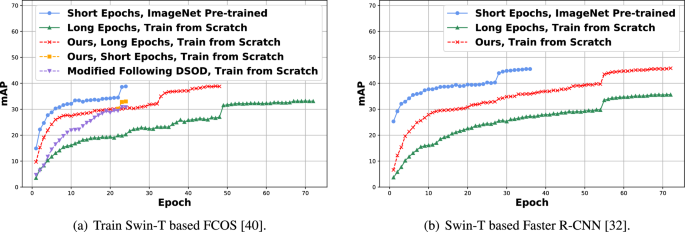
Modeling in computer vision has long been dominated by convolutional neural networks (CNNs). Recently, in light of the excellent performance of self-attention mechanism in the language field, transformers tailored for visual data have drawn significant attention and triumphed over CNNs in various vision tasks. These vision transformers heavily rely on large-scale pre-training to achieve competitive accuracy, which not only hinders the freedom of architectural design in downstream tasks like object detection, but also causes learning bias and domain mismatch in the fine-tuning stages. To this end, we aim to get rid of the “pre-train and fine-tune” paradigm of vision transformer and train transformer based object detector from scratch. Some earlier works in the CNNs era have successfully trained CNNs based detectors without pre-training, unfortunately, their findings do not generalize well when the backbone is switched from CNNs to a vision transformer. Instead of proposing a specific vision transformer based detector, in this work, our goal is to reveal the insights of training vision transformer based detectors from scratch. In particular, we expect those insights to help other researchers and practitioners, and inspire more interesting research in other fields, such as remote sensing, visual-linguistic pre-training, etc. One of the key findings is that both architectural changes and more epochs play critical roles in training vision transformer based detectors from scratch. Experiments on the MS COCO dataset demonstrate that vision transformer based detectors trained from scratch can also achieve similar performance to their counterparts with ImageNet pre-training.
中文翻译:
从头开始训练目标检测器:Vision Transformer 时代的实证研究
计算机视觉建模长期以来一直由卷积神经网络(CNN)主导。最近,鉴于自注意力机制在语言领域的出色表现,为视觉数据量身定制的 Transformer 引起了极大的关注,并在各种视觉任务中战胜了 CNN。这些视觉转换器严重依赖大规模预训练来实现有竞争力的准确性,这不仅阻碍了目标检测等下游任务中架构设计的自由度,而且还导致微调阶段的学习偏差和领域不匹配。为此,我们的目标是从头开始摆脱基于视觉变压器和训练变压器的目标检测器的“预训练和微调”范式。CNN 时代的一些早期工作已经成功地在没有预训练的情况下训练了基于 CNN 的检测器,不幸的是,当主干从 CNN 切换到视觉 Transformer 时,他们的发现并不能很好地推广。在这项工作中,我们的目标不是提出基于特定视觉变换器的检测器,而是揭示从头开始训练基于视觉变换器的检测器的见解。特别是,我们希望这些见解能够帮助其他研究人员和从业者,并激发其他领域更有趣的研究,例如遥感、视觉语言预训练等。主要发现之一是架构变化和更多时代在从头开始训练基于视觉变换器的探测器方面发挥着关键作用。MS COCO 数据集上的实验表明,从头开始训练的基于视觉变换器的检测器也可以实现与 ImageNet 预训练的对应检测器相似的性能。


























 京公网安备 11010802027423号
京公网安备 11010802027423号