当前位置:
X-MOL 学术
›
Photogramm. Rec.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
PL-Pose: robust camera localisation based on combined point and line features using control images
The Photogrammetric Record ( IF 2.4 ) Pub Date : 2024-02-28 , DOI: 10.1111/phor.12481 Zhihua Xu 1, 2 , Yiru Niu 3 , Yan Cui 1 , Rongjun Qin 4, 5 , Wenbin Sun 1
The Photogrammetric Record ( IF 2.4 ) Pub Date : 2024-02-28 , DOI: 10.1111/phor.12481 Zhihua Xu 1, 2 , Yiru Niu 3 , Yan Cui 1 , Rongjun Qin 4, 5 , Wenbin Sun 1
Affiliation
|
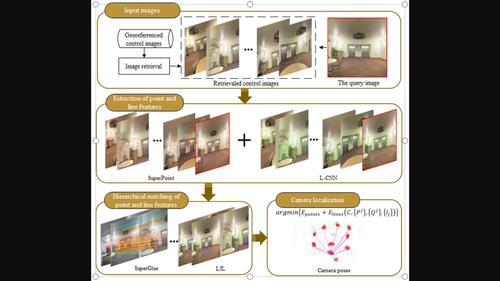
Camera localisation is an essential task in the field of computer vision. The objective is to determine the precise position and orientation of one newly introduced camera station based on a collection of control images that are geographically referenced. Traditional feature-based approaches have been found to face difficulties when confronted with the task of localising images that exhibit significant disparities in viewpoint. Modern deep learning approaches, on the contrary, aim to directly regress camera poses from input image content, being holistic to remedy the problem of viewpoint disparities. This paper posits that although deep networks possess the ability to learn robust and invariant visual features, the incorporation of geometry models can provide rigorous constraints in the process of pose estimation. Following the classic structure-from-motion (SfM) pipeline, we propose a PL-Pose framework to perform camera localisation. First, to improve feature correlations for images with large viewpoint disparities, we perform the combination of point and line features based on a deep learning framework and geometric relation of wireframes. Then, a cost function is constructed using the combined point and line features in order to impose constraints on the bundle adjustment process. Finally, the camera pose parameters and 3D points are estimated through an iterative optimisation process. We verify the accuracy of the PL-Pose approach through the utilisation of two datasets, that is, the publicly available S3DIS dataset and the self-collected dataset CUMTB_Campus. The experimental results demonstrate that in both indoor and outdoor scenes, our PL-Pose method can achieve localisation errors of less than 1 m for 82% of the test points. In contrast, the other four comparison methods yield a best result of merely 72%. Meanwhile, the PL-Pose method can successfully obtain the camera pose parameters in all the scenes with small or large viewpoint disparities, indicating its good stability and adaptability.
中文翻译:

PL-Pose:使用控制图像基于组合点和线特征的鲁棒相机定位
相机定位是计算机视觉领域的一项重要任务。目标是根据地理参考的控制图像集合确定新引入的摄像机站的精确位置和方向。人们发现传统的基于特征的方法在面临定位具有显着视点差异的图像的任务时面临困难。相反,现代深度学习方法的目标是直接从输入图像内容回归相机姿势,整体解决视点差异问题。本文认为,虽然深度网络具有学习鲁棒且不变的视觉特征的能力,但几何模型的结合可以在姿态估计过程中提供严格的约束。遵循经典的运动结构 (SfM) 流程,我们提出了一个 PL-Pose 框架来执行相机定位。首先,为了提高视点差异较大的图像的特征相关性,我们基于深度学习框架和线框的几何关系进行点和线特征的组合。然后,使用组合的点和线特征构建成本函数,以便对束调整过程施加约束。最后,通过迭代优化过程估计相机位姿参数和 3D 点。我们通过使用两个数据集(即公开的 S3DIS 数据集和自行收集的数据集 CUMTB_Campus)验证 PL-Pose 方法的准确性。实验结果表明,在室内和室外场景中,我们的PL-Pose方法可以实现82%的测试点的定位误差小于1 m。相比之下,其他四种比较方法的最佳结果仅为 72%。同时,PL-Pose方法能够在所有视点视差较小或较大的场景下成功获取相机位姿参数,表明其具有良好的稳定性和适应性。
更新日期:2024-02-28
中文翻译:
PL-Pose:使用控制图像基于组合点和线特征的鲁棒相机定位
相机定位是计算机视觉领域的一项重要任务。目标是根据地理参考的控制图像集合确定新引入的摄像机站的精确位置和方向。人们发现传统的基于特征的方法在面临定位具有显着视点差异的图像的任务时面临困难。相反,现代深度学习方法的目标是直接从输入图像内容回归相机姿势,整体解决视点差异问题。本文认为,虽然深度网络具有学习鲁棒且不变的视觉特征的能力,但几何模型的结合可以在姿态估计过程中提供严格的约束。遵循经典的运动结构 (SfM) 流程,我们提出了一个 PL-Pose 框架来执行相机定位。首先,为了提高视点差异较大的图像的特征相关性,我们基于深度学习框架和线框的几何关系进行点和线特征的组合。然后,使用组合的点和线特征构建成本函数,以便对束调整过程施加约束。最后,通过迭代优化过程估计相机位姿参数和 3D 点。我们通过使用两个数据集(即公开的 S3DIS 数据集和自行收集的数据集 CUMTB_Campus)验证 PL-Pose 方法的准确性。实验结果表明,在室内和室外场景中,我们的PL-Pose方法可以实现82%的测试点的定位误差小于1 m。相比之下,其他四种比较方法的最佳结果仅为 72%。同时,PL-Pose方法能够在所有视点视差较小或较大的场景下成功获取相机位姿参数,表明其具有良好的稳定性和适应性。


























 京公网安备 11010802027423号
京公网安备 11010802027423号