Security Journal ( IF 1.701 ) Pub Date : 2024-03-01 , DOI: 10.1057/s41284-024-00416-6 Betelhem Zewdu Wubineh
|
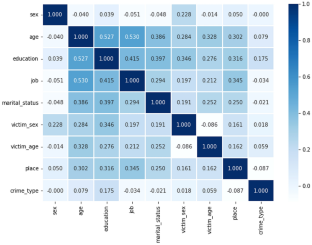
Crime is a socioeconomic problem that affects the quality of life and economic growth of a country, and it continues to increase. Crime prevention and prediction are systematic approaches used to locate and analyze historical data to identify trends that can be employed in identifying crimes and criminals. The objective of this study is to predict the type of crime that occurred in the city and identify the important features that make this prediction using a machine learning technique. For this experimental investigation, a supervised learning method was used to classify the types of crimes based on the final labelled class that indicates which type of crime is committed. Thus, decision tree (DT), random forest (RF), and K-nearest neighbor (KNN) algorithms are utilized along with the Python programming language in the Jupyter notebook environment. A total of 1400 records and nine attributes were used, and the data were split into training and testing sets, with 80% allocated to training and 20% for testing. The decision tree achieved an accuracy score of 84%, followed by the random forest at 86.07% and K-nearest neighbor at 81%. Besides this, the job of the offender, the victim’s age, and the offender’s age are the important features that cause crime. Therefore, it can be concluded that the use of machine learning to analyze historical data and the random forest algorithm to classify crimes yields promising results in predicting the type of crime.
中文翻译:
在 Hossana 警察委员会案例中使用机器学习方法进行犯罪分析和预测
犯罪是影响一个国家生活质量和经济增长的社会经济问题,而且犯罪率持续增加。犯罪预防和预测是用于定位和分析历史数据以识别可用于识别犯罪和罪犯的趋势的系统方法。本研究的目的是预测城市中发生的犯罪类型,并使用机器学习技术确定做出此预测的重要特征。在本实验调查中,使用监督学习方法根据最终标记的类别(表明所实施的犯罪类型)对犯罪类型进行分类。因此,决策树 (DT)、随机森林 (RF) 和 K 最近邻 (KNN) 算法与 Jupyter Notebook 环境中的 Python 编程语言一起使用。总共使用了 1400 条记录和 9 个属性,并将数据分为训练集和测试集,其中 80% 分配给训练,20% 用于测试。决策树的准确度得分为 84%,其次是随机森林(86.07%)和 K 最近邻(81%)。除此之外,犯罪人的职业、受害人的年龄、犯罪人的年龄也是引发犯罪的重要特征。因此,可以得出结论,使用机器学习分析历史数据和随机森林算法对犯罪进行分类在预测犯罪类型方面取得了可喜的结果。


























 京公网安备 11010802027423号
京公网安备 11010802027423号