Automatic Control and Computer Sciences Pub Date : 2024-03-07 , DOI: 10.3103/s0146411624010115 Shuangshuang Yu
|
Abstract
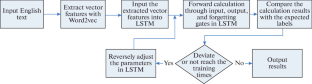
Accurate identification and analysis of semantics is beneficial for processing English texts effectively. This article briefly introduced Word2vec, which was used to extract semantic feature vectors from English texts, and the long short-term memory (LSTM) algorithm, which was used for semantic recognition of English texts. The relevant English comment texts were crawled from the Amazon movie database and used in a simulation experiment. The simulation experiment compared three algorithms: back propagation, recurrent neural network (RNN), and LSTM. The results showed that the LSTM algorithm’s recognition results for the part-of-speech and sentiment inclination of English texts were consistent with the label results. As the length of the English text increased, the recognition accuracy of all three algorithms decreased, and the LSTM algorithm had the smallest decrease. For the same length of English text, the LSTM algorithm had the highest accuracy in identifying part-of-speech and sentiment inclination, followed by the RNN algorithm, and the BP algorithm had the lowest. In terms of recognition time, the LSTM algorithm was the least.
中文翻译:
智能算法下英语文本语义特征的提取与分析
摘要
准确的语义识别和分析有利于有效地处理英语文本。本文简要介绍了用于从英语文本中提取语义特征向量的Word2vec,以及用于英语文本语义识别的长短期记忆(LSTM)算法。从亚马逊电影数据库中爬取相关英文评论文本并用于模拟实验。仿真实验比较了反向传播、循环神经网络(RNN)和LSTM三种算法。结果表明,LSTM算法对英语文本的词性和情感倾向的识别结果与标签结果一致。随着英文文本长度的增加,三种算法的识别准确率均有所下降,其中LSTM算法下降幅度最小。对于相同长度的英文文本,LSTM 算法识别词性和情感倾向的准确率最高,RNN 算法次之,BP 算法最低。从识别时间来看,LSTM算法是最少的。


























 京公网安备 11010802027423号
京公网安备 11010802027423号