Education and Information Technologies ( IF 3.666 ) Pub Date : 2024-03-09 , DOI: 10.1007/s10639-024-12589-z Pavel Stefanovič , Birutė Pliuskuvienė , Urtė Radvilaitė , Simona Ramanauskaitė
|
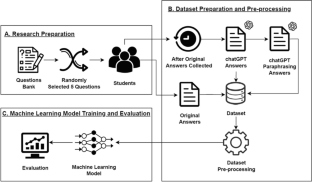
The public availability of large language models, such as chatGPT, brings additional possibilities and challenges to education. Education institutions have to identify when large language models are used and when text is generated by the student itself. In this paper, chatGPT usage in students' answers is investigated. The main aim of the research was to build a machine learning model that could be used in the evaluation of students' answers to open-ended questions written in the Lithuanian language. The model should determine whether the answers were originally written students or answered with the help of chatGPT. A new dataset of student answers has been collected in to train machine learning models. The dataset consists of original student answers, chatGPT answers, and paraphrased chatGPT answers. A total of more than 1000 answers have been prepared. 24 combinations of text pre-processing algorithms have been analyzed. In text pre-processing, the main focus was on various tokenization methods, such as the Bag of Words and Ngrams, the stemming algorithm, and the stop words list. For the analyzed dataset, these pre-processing methods were more effective than application of multilanguage BERT for document embedding. Based on the features/properties of the dataset, the following learning algorithms have been investigated: artificial neural networks, decision trees, random forest, gradient boosting trees, k-nearest neighbours, and naive Bayes. The main results show that the highest accuracy of 87% in some cases can be obtained using gradient boosting trees, random forests, and artificial neural network algorithms. The lowest accuracy has been obtained using the k-nearest neighbouring algorithm. Furthermore, the results of experimental research suggest that the usage of chatGPT in student answers can be automatically identified.
中文翻译:
用于检测学生开放式问题答案中的 chatGPT 使用情况的机器学习模型:立陶宛语案例
大型语言模型(例如 chatGPT)的公开可用,给教育带来了更多的可能性和挑战。教育机构必须确定何时使用大型语言模型以及何时由学生自己生成文本。本文调查了 chatGPT 在学生答案中的使用情况。该研究的主要目的是建立一个机器学习模型,可用于评估学生对用立陶宛语编写的开放式问题的回答。该模型应该确定答案是学生最初写的还是在 chatGPT 的帮助下回答的。已收集学生答案的新数据集来训练机器学习模型。该数据集包含原始学生答案、chatGPT 答案和释义的 chatGPT 答案。总共准备了1000多个答案。分析了 24 种文本预处理算法的组合。在文本预处理中,主要关注各种标记化方法,例如Bag of Words和Ngrams、词干算法和停用词列表。对于分析的数据集,这些预处理方法比应用多语言 BERT 进行文档嵌入更有效。基于数据集的特征/属性,研究了以下学习算法:人工神经网络、决策树、随机森林、梯度提升树、k-最近邻和朴素贝叶斯。主要结果表明,使用梯度提升树、随机森林和人工神经网络算法在某些情况下可以获得 87% 的最高准确率。使用 k 最近邻算法获得了最低的精度。此外,实验研究结果表明,可以自动识别学生答案中chatGPT的使用情况。


























 京公网安备 11010802027423号
京公网安备 11010802027423号