当前位置:
X-MOL 学术
›
Comput. Struct. Biotechnol. J.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Machine learning framework to extract the biomarker potential of plasma IgG N-glycans towards disease risk stratification
Computational and Structural Biotechnology Journal ( IF 6 ) Pub Date : 2024-03-11 , DOI: 10.1016/j.csbj.2024.03.008 Konstantinos Flevaris , Joseph Davies , Shoh Nakai , Frano Vučković , Gordan Lauc , Malcolm G. Dunlop , Cleo Kontoravdi
Computational and Structural Biotechnology Journal ( IF 6 ) Pub Date : 2024-03-11 , DOI: 10.1016/j.csbj.2024.03.008 Konstantinos Flevaris , Joseph Davies , Shoh Nakai , Frano Vučković , Gordan Lauc , Malcolm G. Dunlop , Cleo Kontoravdi
|
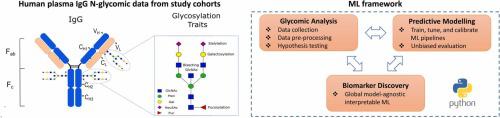
Effective management of chronic diseases and cancer can greatly benefit from disease-specific biomarkers that enable informative screening and timely diagnosis. IgG N-glycans found in human plasma have the potential to be minimally invasive disease-specific biomarkers for all stages of disease development due to their plasticity in response to various genetic and environmental stimuli. Data analysis and machine learning (ML) approaches can assist in harnessing the potential of IgG glycomics towards biomarker discovery and the development of reliable predictive tools for disease screening. This study proposes an ML-based N-glycomic analysis framework that can be employed to build, optimise, and evaluate multiple ML pipelines to stratify patients based on disease risk in an interpretable manner. To design and test this framework, a published colorectal cancer (CRC) dataset from the Study of Colorectal Cancer in Scotland (SOCCS) cohort (1999–2006) was used. In particular, among the different pipelines tested, an XGBoost-based ML pipeline, which was tuned using multi-objective optimisation, calibrated using an inductive Venn-Abers predictor (IVAP), and evaluated via a nested cross-validation (NCV) scheme, achieved a mean area under the Receiver Operating Characteristic Curve (AUC-ROC) of 0.771 when classifying between age-, and sex-matched healthy controls and CRC patients. This performance suggests the potential of using the relative abundance of IgG N-glycans to define populations at elevated CRC risk who merit investigation or surveillance. Finally, the IgG N-glycans that highly impact CRC classification decisions were identified using a global model-agnostic interpretability technique, namely Accumulated Local Effects (ALE). We envision that open-source computational frameworks, such as the one presented herein, will be useful in supporting the translation of glycan-based biomarkers into clinical applications.
中文翻译:

机器学习框架可提取血浆 IgG N-聚糖的生物标志物潜力,进行疾病风险分层
慢性病和癌症的有效管理可以极大地受益于疾病特异性生物标志物,这些生物标志物可以提供信息筛查和及时诊断。人血浆中发现的 IgG N-聚糖由于其对各种遗传和环境刺激的可塑性,有可能成为疾病发展各个阶段的微创疾病特异性生物标志物。数据分析和机器学习 (ML) 方法可以帮助利用 IgG 糖组学的潜力来发现生物标志物和开发用于疾病筛查的可靠预测工具。本研究提出了一种基于 ML 的 N 糖组分析框架,可用于构建、优化和评估多个 ML 流程,以可解释的方式根据疾病风险对患者进行分层。为了设计和测试该框架,使用了苏格兰结直肠癌研究 (SOCCS) 队列 (1999-2006) 中已发布的结直肠癌 (CRC) 数据集。特别是,在测试的不同管道中,基于 XGBoost 的 ML 管道使用多目标优化进行调整,使用归纳 Venn-Abers 预测器 (IVAP) 进行校准,并通过嵌套交叉验证 (NCV) 方案进行评估,在对年龄和性别匹配的健康对照组和 CRC 患者进行分类时,受试者工作特征曲线 (AUC-ROC) 下的平均面积 (AUC-ROC) 达到 0.771。这一表现表明,可以利用 IgG N-聚糖的相对丰度来定义值得调查或监测的 CRC 风险较高的人群。最后,使用与模型无关的全局可解释性技术,即累积局部效应 (ALE),确定了对 CRC 分类决策有重大影响的 IgG N-聚糖。我们设想开源计算框架,例如本文中提出的框架,将有助于支持基于聚糖的生物标志物转化为临床应用。
更新日期:2024-03-11
中文翻译:
机器学习框架可提取血浆 IgG N-聚糖的生物标志物潜力,进行疾病风险分层
慢性病和癌症的有效管理可以极大地受益于疾病特异性生物标志物,这些生物标志物可以提供信息筛查和及时诊断。人血浆中发现的 IgG N-聚糖由于其对各种遗传和环境刺激的可塑性,有可能成为疾病发展各个阶段的微创疾病特异性生物标志物。数据分析和机器学习 (ML) 方法可以帮助利用 IgG 糖组学的潜力来发现生物标志物和开发用于疾病筛查的可靠预测工具。本研究提出了一种基于 ML 的 N 糖组分析框架,可用于构建、优化和评估多个 ML 流程,以可解释的方式根据疾病风险对患者进行分层。为了设计和测试该框架,使用了苏格兰结直肠癌研究 (SOCCS) 队列 (1999-2006) 中已发布的结直肠癌 (CRC) 数据集。特别是,在测试的不同管道中,基于 XGBoost 的 ML 管道使用多目标优化进行调整,使用归纳 Venn-Abers 预测器 (IVAP) 进行校准,并通过嵌套交叉验证 (NCV) 方案进行评估,在对年龄和性别匹配的健康对照组和 CRC 患者进行分类时,受试者工作特征曲线 (AUC-ROC) 下的平均面积 (AUC-ROC) 达到 0.771。这一表现表明,可以利用 IgG N-聚糖的相对丰度来定义值得调查或监测的 CRC 风险较高的人群。最后,使用与模型无关的全局可解释性技术,即累积局部效应 (ALE),确定了对 CRC 分类决策有重大影响的 IgG N-聚糖。我们设想开源计算框架,例如本文中提出的框架,将有助于支持基于聚糖的生物标志物转化为临床应用。


























 京公网安备 11010802027423号
京公网安备 11010802027423号