当前位置:
X-MOL 学术
›
IET Image Process.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Salient object detection in egocentric videos
IET Image Processing ( IF 2.3 ) Pub Date : 2024-03-13 , DOI: 10.1049/ipr2.13080 Hao Zhang 1 , Haoran Liang 1 , Xing Zhao 1 , Jian Liu 1 , Ronghua Liang 1
IET Image Processing ( IF 2.3 ) Pub Date : 2024-03-13 , DOI: 10.1049/ipr2.13080 Hao Zhang 1 , Haoran Liang 1 , Xing Zhao 1 , Jian Liu 1 , Ronghua Liang 1
Affiliation
|
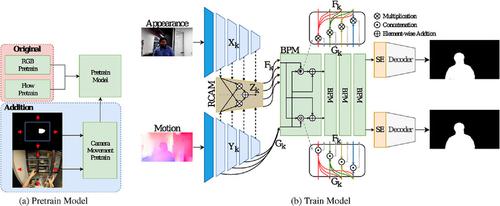
In the realm of video salient object detection (VSOD), the majority of research has traditionally been centered on third-person perspective videos. However, this focus overlooks the unique requirements of certain first-person tasks, such as autonomous driving or robot vision. To bridge this gap, a novel dataset and a camera-based VSOD model, CaMSD, specifically designed for egocentric videos, is introduced. First, the SalEgo dataset, comprising 17,400 fully annotated frames for video salient object detection, is presented. Second, a computational model that incorporates a camera movement module is proposed, designed to emulate the patterns observed when humans view videos. Additionally, to achieve precise segmentation of a single salient object during switches between salient objects, as opposed to simultaneously segmenting two objects, a saliency enhancement module based on the Squeeze and Excitation Block is incorporated. Experimental results show that the approach outperforms other state-of-the-art methods in egocentric video salient object detection tasks. Dataset and codes can be found at https://github.com/hzhang1999/SalEgo.
中文翻译:

以自我为中心的视频中的显着对象检测
在视频显着目标检测(VSOD)领域,大多数研究传统上都集中在第三人称视角视频上。然而,这种关注忽视了某些第一人称任务的独特要求,例如自动驾驶或机器人视觉。为了弥补这一差距,引入了专门为以自我为中心的视频设计的新颖数据集和基于相机的 VSOD 模型CaMSD 。首先,介绍了SalEgo数据集,其中包含 17,400 个用于视频显着对象检测的完全注释帧。其次,提出了一种包含相机运动模块的计算模型,旨在模拟人类观看视频时观察到的模式。此外,为了在显着对象之间切换期间实现单个显着对象的精确分割,而不是同时分割两个对象,结合了基于挤压和激励块的显着性增强模块。实验结果表明,该方法在以自我为中心的视频显着对象检测任务中优于其他最先进的方法。数据集和代码可以在https://github.com/hzhang1999/SalEgo找到。
更新日期:2024-03-14
中文翻译:
以自我为中心的视频中的显着对象检测
在视频显着目标检测(VSOD)领域,大多数研究传统上都集中在第三人称视角视频上。然而,这种关注忽视了某些第一人称任务的独特要求,例如自动驾驶或机器人视觉。为了弥补这一差距,引入了专门为以自我为中心的视频设计的新颖数据集和基于相机的 VSOD 模型CaMSD 。首先,介绍了SalEgo数据集,其中包含 17,400 个用于视频显着对象检测的完全注释帧。其次,提出了一种包含相机运动模块的计算模型,旨在模拟人类观看视频时观察到的模式。此外,为了在显着对象之间切换期间实现单个显着对象的精确分割,而不是同时分割两个对象,结合了基于挤压和激励块的显着性增强模块。实验结果表明,该方法在以自我为中心的视频显着对象检测任务中优于其他最先进的方法。数据集和代码可以在https://github.com/hzhang1999/SalEgo找到。


























 京公网安备 11010802027423号
京公网安备 11010802027423号