当前位置:
X-MOL 学术
›
Fish. Res.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Estimating catch within integrated stock assessments: Distinguishing truth from error in sparse-spike data
Fisheries Research ( IF 2.4 ) Pub Date : 2024-03-16 , DOI: 10.1016/j.fishres.2024.106994 Erik H. Williams , Kyle W. Shertzer
Fisheries Research ( IF 2.4 ) Pub Date : 2024-03-16 , DOI: 10.1016/j.fishres.2024.106994 Erik H. Williams , Kyle W. Shertzer
|
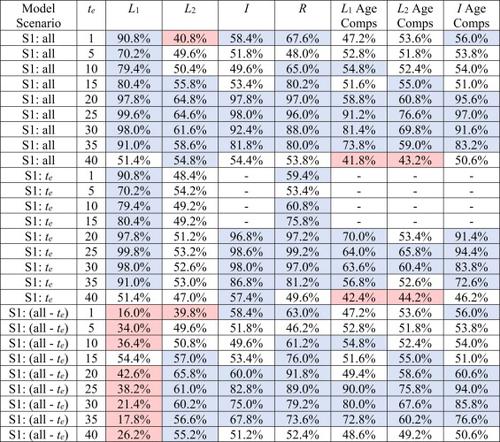
Collecting accurate information on catch levels from marine recreational fishing can be challenging and often results in highly uncertain estimates of landings and discards. Sparse spikes are a common characteristic of these data, with isolated values much higher (e.g., 2–4 times) the surrounding values in a time series of annual estimates. In many cases, it is unclear whether these spikes represent observation error or true, even if anomalous, values. Utilizing multiple data sources simultaneously, integrated stock assessment models may be able to distinguish truth from error in sparse-spike catch estimates, however this supposition has not been well tested. Here, we developed a simulation study to elucidate conditions under which an integrated stock assessment model might perform well (or poorly) when confronted with sparse-spike catch estimates. We found that unconstrained estimation could distinguish truth from error in anomalous values, but only under specific conditions of supporting data. If the anomaly is known to be biased high, estimated catches can get closer to the true value. If the error mechanism is unknown, our results suggest that the true underlying value of a sparse spike is only recoverable when other input data are highly accurate, primarily a reliable index of abundance, but also age composition data in the same year.
中文翻译:

综合种群评估中的渔获量估算:区分稀疏峰值数据中的真相与错误
收集有关海洋休闲渔业捕捞量的准确信息可能具有挑战性,并且通常会导致对上岸量和丢弃量的估计高度不确定。稀疏尖峰是这些数据的一个共同特征,在年度估计的时间序列中,孤立值远高于周围值(例如,2-4 倍)。在许多情况下,尚不清楚这些尖峰是否代表观察误差或真实值(即使是异常值)。同时利用多个数据源,综合种群评估模型也许能够区分稀疏峰值捕捞量估计中的真实与错误,但这种假设尚未得到充分测试。在这里,我们开展了一项模拟研究,以阐明综合种群评估模型在面对稀疏峰值捕捞量估计时可能表现良好(或较差)的条件。我们发现无约束估计可以区分异常值的真实与错误,但前提是有特定的数据支持条件。如果已知异常偏高,则估计渔获量可以更接近真实值。如果错误机制未知,我们的结果表明,只有当其他输入数据高度准确(主要是可靠的丰度指数,但也包括同年的年龄构成数据)时,稀疏尖峰的真正潜在价值才能恢复。
更新日期:2024-03-16
中文翻译:
综合种群评估中的渔获量估算:区分稀疏峰值数据中的真相与错误
收集有关海洋休闲渔业捕捞量的准确信息可能具有挑战性,并且通常会导致对上岸量和丢弃量的估计高度不确定。稀疏尖峰是这些数据的一个共同特征,在年度估计的时间序列中,孤立值远高于周围值(例如,2-4 倍)。在许多情况下,尚不清楚这些尖峰是否代表观察误差或真实值(即使是异常值)。同时利用多个数据源,综合种群评估模型也许能够区分稀疏峰值捕捞量估计中的真实与错误,但这种假设尚未得到充分测试。在这里,我们开展了一项模拟研究,以阐明综合种群评估模型在面对稀疏峰值捕捞量估计时可能表现良好(或较差)的条件。我们发现无约束估计可以区分异常值的真实与错误,但前提是有特定的数据支持条件。如果已知异常偏高,则估计渔获量可以更接近真实值。如果错误机制未知,我们的结果表明,只有当其他输入数据高度准确(主要是可靠的丰度指数,但也包括同年的年龄构成数据)时,稀疏尖峰的真正潜在价值才能恢复。


























 京公网安备 11010802027423号
京公网安备 11010802027423号