Journal of Real-Time Image Processing ( IF 3 ) Pub Date : 2024-03-25 , DOI: 10.1007/s11554-024-01443-7 Peng Zhang , Lijia Dong , Xinlei Zhao , Weimin Lei , Wei Zhang
|
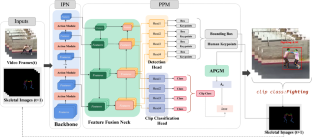
Violent behavior detection (VioBD), as a special action recognition task, aims to detect violent behaviors in videos, such as mutual fighting and assault. Some progress has been made in the research of violence detection, but the existing methods have poor real-time performance and the algorithm performance is limited by the interference of complex backgrounds and the occlusion of dense crowds. To solve the above problems, we propose an end-to-end real-time violence detection framework based on 2D CNNs. First, we propose a lightweight skeletal image (SI) as the input modality, which can obtain the human body posture information and richer contextual information, and at the same time remove the background interference. As tested, at the same accuracy, the resolution of SI modality is only one-third of that of RGB modality, which greatly improves the real-time performance of model training and inference, and at the same resolution, SI modality has higher inaccuracy. Second, we also design a parallel prediction module (PPM), which can simultaneously obtain the single image detection results and the inter-frame motion information of the video, which can improve the real-time performance of the algorithm compared with the traditional “detect the image first, understand the video later" mode. In addition, we propose an auxiliary parameter generation module (APGM) with both efficiency and accuracy, APGM is a 2D CNNs-based video understanding module for weighting the spatial information of the video features, processing speed can reach 30–40 frames per second, and compared with models such as CNN-LSTM (Iqrar et al., Aamir: Cnn-lstm based smart real-time video surveillance system. In: 2022 14th International Conference on Mathematics, Actuarial, Science, Computer Science and Statistics (MACS), pages 1–5. IEEE, 2022) and Ludl et al. (Cristóbal: Simple yet efficient real-time pose-based action recognition. In: 2019 IEEE Intelligent Transportation Systems Conference (ITSC), pages 581–588. IEEE, 1999), the propagation effect speed can be increased by an average of \(3 \sim 20\) frames per second per group of clips, which further improves the video motion detection efficiency and accuracy, greatly improving real-time performance. We conducted experiments on some challenging benchmarks, and RVBDN can maintain excellent speed and accuracy in long-term interactions, and are able to meet real-time requirements in methods for violence detection and spatio-temporal action detection. Finally, we update our proposed new dataset on violence detection images (violence image dataset). Dataset is available at https://github.com/ChinaZhangPeng/Violence-Image-Dataset
中文翻译:
基于 2D CNN 的实时暴力行为检测端到端框架
暴力行为检测(VioBD)作为一种特殊的动作识别任务,旨在检测视频中的暴力行为,例如互相打架、殴打等。暴力检测研究取得了一定进展,但现有方法实时性较差,算法性能受到复杂背景干扰和密集人群遮挡的限制。为了解决上述问题,我们提出了一种基于 2D CNN 的端到端实时暴力检测框架。首先,我们提出一种轻量级骨骼图像(SI)作为输入模态,可以获得人体姿势信息和更丰富的上下文信息,同时去除背景干扰。经测试,在相同精度下,SI模态的分辨率仅为RGB模态的三分之一,大大提高了模型训练和推理的实时性,而在相同分辨率下,SI模态的不准确度更高。其次,我们还设计了并行预测模块(PPM),可以同时获得单图像检测结果和视频的帧间运动信息,与传统的“检测”相比,可以提高算法的实时性。 “先图像,后理解视频”模式。此外,我们提出了一种兼具效率和准确性的辅助参数生成模块(APGM),APGM是一个基于2D CNNs的视频理解模块,用于对视频特征的空间信息进行加权,处理速度可以达到每秒30-40帧,并与CNN-LSTM等模型进行比较(Iqrar等人,Aamir:基于Cnn-lstm的智能实时视频监控系统。见:2022年第14届国际数学会议,精算) ,科学、计算机科学和统计学 (MACS),第 1-5 页。IEEE,2022)和 Ludl 等人。(Cristóbal:简单而高效的实时基于姿势的动作识别。见:2019 年 IEEE 智能交通系统会议 (ITSC) ),第 581-588 页。 IEEE,1999),每组剪辑的传播效果速度平均可以提高\(3\sim 20\)帧/秒,进一步提高了视频运动检测效率和准确性,大大提高了实时性能。我们在一些具有挑战性的基准上进行了实验,RVBDN 在长期交互中可以保持出色的速度和准确性,并且能够满足暴力检测和时空动作检测方法的实时要求。最后,我们更新了我们提出的关于暴力检测图像的新数据集(暴力图像数据集)。数据集可在 https://github.com/ChinaZhangPeng/Violence-Image-Dataset 获取


























 京公网安备 11010802027423号
京公网安备 11010802027423号