Applied Mathematics and Optimization ( IF 1.8 ) Pub Date : 2024-03-26 , DOI: 10.1007/s00245-024-10118-5 Łukasz Stettner
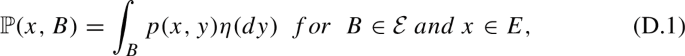
|
Controlled discrete time Markov processes are studied first with long run general discounting functional. It is shown that optimal strategies for average reward per unit time problem are also optimal for average generally discounting functional. Then long run risk sensitive reward functional with general discounting is considered. When risk factor is positive then optimal value of such reward functional is dominated by the reward functional corresponding to the long run risk sensitive control. In the case of negative risk factor we get an asymptotical result, which says that optimal average reward per unit time control is nearly optimal for long run risk sensitive reward functional with general discounting, assuming that risk factor is close to 0. For this purpose we show in Appendix upper estimates for large deviations of weighted empirical measures, which are of independent interest.
中文翻译:
一般贴现的长期随机控制问题
首先研究了受控离散时间马尔可夫过程和长期一般贴现函数。结果表明,单位时间平均奖励问题的最优策略对于平均一般折扣函数也是最优的。然后考虑具有一般贴现的长期风险敏感奖励函数。当风险因子为正时,这种奖励函数的最优值由与长期风险敏感控制相对应的奖励函数主导。在风险因子为负的情况下,我们得到一个渐近结果,这表明,假设风险因子接近 0,则单位时间控制的最优平均奖励对于具有一般贴现的长期风险敏感奖励函数来说几乎是最优的。为此,我们在附录中显示了加权经验测量的大偏差的上估计,这是独立感兴趣的。


























 京公网安备 11010802027423号
京公网安备 11010802027423号