The Journal of Supercomputing ( IF 3.3 ) Pub Date : 2024-04-04 , DOI: 10.1007/s11227-024-06052-6 Shiyu Liu , Qicheng Liu
|
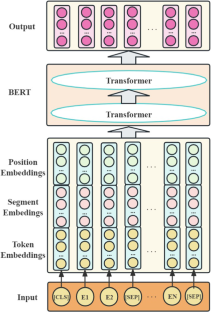
Sentiment analysis is one of the core tasks in natural language processing, and its main goal is to identify and classify the sentiment tendencies contained in texts. Traditional sentiment analysis methods and shallow models often fail to capture the rich semantic information and contextual relationships in text, while increasing the network depth is prone to problems such as network degradation, which has some limitations in terms of accuracy and performance. Based on this foundation, a sentiment analysis model called BERT-Invos (Bidirectional Encoder Representations from Transformers (BERT)-based stacked involutions) is introduced. The model utilizes the dynamic pre-training language model BERT to encode text, enabling rich semantic features and contextual understanding. In addition, the model employs stacked involutions with varying dimensions to extract features and perceive local information, gradually learning different scales and hierarchical representations of the input text. Furthermore, the proposed method incorporates nonlinear activation functions such as ReLU6 and H-Swish to enhance the model’s expression capability and performance, ultimately delivering classification results. In the experiment, a financial news sentiment dataset was utilized for model validation and comparison against other models. The results revealed that the model achieved an accuracy of 96.34% in sentiment analysis tasks, with precision, recall, and F1 score reaching 96.37%, 96.34%, and 96.34%, respectively. Additionally, the loss value could be minimized to 0.07 with stable convergence, thereby enhancing the accuracy of sentiment classification and reducing loss rates. This improvement facilitates better capturing of local patterns in text and addresses the issue of degradation in deep neural networks. Regarding the deep architecture of the proposed model, future work will focus on further exploring optimization techniques for model compression and deployment.
中文翻译:
基于动态预训练和堆叠卷积的情感分析模型
情感分析是自然语言处理的核心任务之一,其主要目标是识别和分类文本中包含的情感倾向。传统的情感分析方法和浅层模型往往无法捕捉文本中丰富的语义信息和上下文关系,而增加网络深度则容易出现网络退化等问题,在准确性和性能方面都有一定的局限性。在此基础上,引入了一种名为 BERT-Invos(基于 Transformers 的双向编码器表示(BERT)的堆叠内卷)的情感分析模型。该模型利用动态预训练语言模型BERT对文本进行编码,实现丰富的语义特征和上下文理解。此外,该模型采用不同维度的堆叠卷积来提取特征并感知局部信息,逐渐学习输入文本的不同尺度和层次表示。此外,该方法还结合了ReLU6和H-Swish等非线性激活函数来增强模型的表达能力和性能,最终提供分类结果。在实验中,利用财经新闻情绪数据集进行模型验证并与其他模型进行比较。结果显示,该模型在情感分析任务中的准确率达到了96.34%,查准率、召回率和F1分数分别达到96.37%、96.34%和96.34%。此外,在稳定收敛的情况下,损失值可以最小化到0.07,从而提高情感分类的准确性并降低损失率。这一改进有助于更好地捕获文本中的局部模式,并解决深度神经网络的退化问题。关于所提出模型的深层架构,未来的工作将集中于进一步探索模型压缩和部署的优化技术。


























 京公网安备 11010802027423号
京公网安备 11010802027423号