The Visual Computer ( IF 3.5 ) Pub Date : 2024-04-08 , DOI: 10.1007/s00371-024-03305-6 Wenji Yang , Liping Xie , Wenbin Qian , Canghai Wu , Hongyun Yang
|
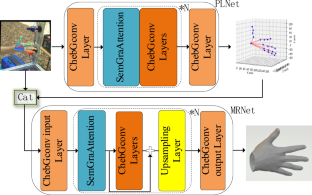
Recently, graph convolution networks have become the mainstream methods in 3D hand pose and mesh estimation, but there are still some issues hindering its further development. First, the way that previous researchers alleviated small receptive field of vanilla graph convolution by simply stacking multiple GCN layers might lead to over-smoothness of features, thereby misleading the hand pose estimation. Second, most attempts directly reconstructed hand mesh from 3D pose in one step, which ignored the significant gap between sparse pose and dense mesh, resulting in incorrect results and unstable training. To solve these issues, a novel framework integrating multi-head self-attention, spatial-based graph convolution and spectral-based graph convolution for 3D hand pose and mesh estimation is proposed. The proposed framework comprises of two main modules: SemGraAttention and ChebGconv blocks. The SemGraAttention enables all hand joints to interact in global field without weakening the topologies of hand. As a complementary, the ChebGconv formulates implicit semantic relations among joints to further boost performance. In addition, a coarse-to-fine strategy is adopted to reconstruct dense hand mesh from sparse pose step by step, which contributes to refined results and stable training. The extensive evaluations on multiple 3D benchmarks demonstrate that our model outperforms a series of 3D hand pose and mesh estimation approaches.
中文翻译:
基于SSGC和MHSA的粗到精级联3D手重建
近年来,图卷积网络已成为3D手部姿势和网格估计中的主流方法,但仍然存在一些问题阻碍其进一步发展。首先,之前的研究人员通过简单地堆叠多个 GCN 层来缓解普通图卷积的小感受野的方式可能会导致特征过度平滑,从而误导手部姿势估计。其次,大多数尝试直接从 3D 姿势一步重建手部网格,忽略了稀疏姿势和密集网格之间的显着差距,导致结果不正确和训练不稳定。为了解决这些问题,提出了一种集成多头自注意力、基于空间的图卷积和基于频谱的图卷积的新框架,用于 3D 手部姿势和网格估计。所提出的框架由两个主要模块组成:SemGraAttention 和 ChebGconv 块。 SemGraAttention 使所有手部关节能够在全局场中交互,而不会削弱手部的拓扑结构。作为补充,ChebGconv 制定了关节之间的隐式语义关系,以进一步提高性能。此外,采用从粗到细的策略逐步从稀疏姿态重建密集的手部网格,这有助于精细化结果和稳定的训练。对多个 3D 基准的广泛评估表明,我们的模型优于一系列 3D 手部姿势和网格估计方法。


























 京公网安备 11010802027423号
京公网安备 11010802027423号