Nature Medicine ( IF 82.9 ) Pub Date : 2024-04-10 , DOI: 10.1038/s41591-024-02838-6 Ira Ktena , Olivia Wiles , Isabela Albuquerque , Sylvestre-Alvise Rebuffi , Ryutaro Tanno , Abhijit Guha Roy , Shekoofeh Azizi , Danielle Belgrave , Pushmeet Kohli , Taylan Cemgil , Alan Karthikesalingam , Sven Gowal
|
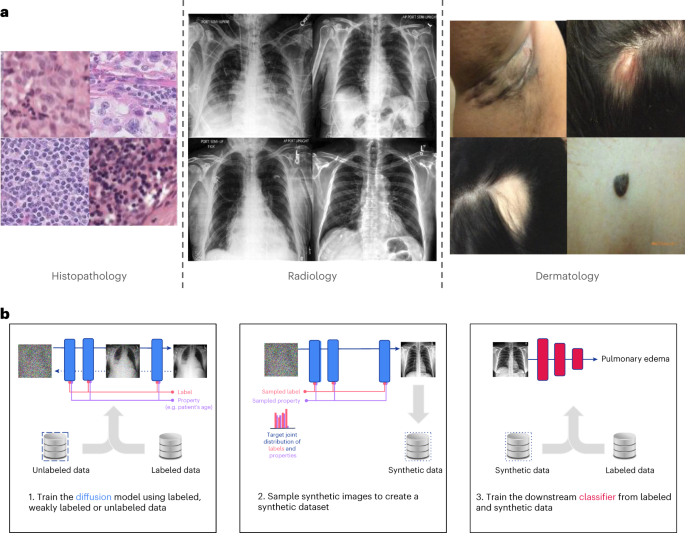
Domain generalization is a ubiquitous challenge for machine learning in healthcare. Model performance in real-world conditions might be lower than expected because of discrepancies between the data encountered during deployment and development. Underrepresentation of some groups or conditions during model development is a common cause of this phenomenon. This challenge is often not readily addressed by targeted data acquisition and ‘labeling’ by expert clinicians, which can be prohibitively expensive or practically impossible because of the rarity of conditions or the available clinical expertise. We hypothesize that advances in generative artificial intelligence can help mitigate this unmet need in a steerable fashion, enriching our training dataset with synthetic examples that address shortfalls of underrepresented conditions or subgroups. We show that diffusion models can automatically learn realistic augmentations from data in a label-efficient manner. We demonstrate that learned augmentations make models more robust and statistically fair in-distribution and out of distribution. To evaluate the generality of our approach, we studied three distinct medical imaging contexts of varying difficulty: (1) histopathology, (2) chest X-ray and (3) dermatology images. Complementing real samples with synthetic ones improved the robustness of models in all three medical tasks and increased fairness by improving the accuracy of clinical diagnosis within underrepresented groups, especially out of distribution.
中文翻译:
生成模型提高了分布变化下医疗分类器的公平性
领域泛化是医疗保健领域机器学习面临的普遍挑战。由于部署和开发期间遇到的数据之间存在差异,实际条件下的模型性能可能低于预期。模型开发过程中某些群体或条件的代表性不足是造成这种现象的常见原因。这一挑战通常不容易通过临床专家的有针对性的数据采集和“标记”来解决,由于条件的稀有或可用的临床专业知识,这可能非常昂贵或实际上是不可能的。我们假设生成人工智能的进步可以帮助以可引导的方式缓解这种未满足的需求,通过合成示例丰富我们的训练数据集,以解决代表性不足的条件或子组的不足。我们证明扩散模型可以以标签有效的方式自动从数据中学习真实的增强。我们证明,学习增强使模型更加稳健,并且在分布内和分布外具有统计上的公平性。为了评估我们方法的通用性,我们研究了三种不同难度的不同医学成像背景:(1) 组织病理学,(2) 胸部 X 射线和 (3) 皮肤病学图像。用合成样本补充真实样本提高了模型在所有三项医疗任务中的稳健性,并通过提高代表性不足的群体(尤其是分布外群体)的临床诊断准确性来提高公平性。


























 京公网安备 11010802027423号
京公网安备 11010802027423号