当前位置:
X-MOL 学术
›
Eng. Appl. Artif. Intell.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
F[formula omitted]Depth: Self-supervised indoor monocular depth estimation via optical flow consistency and feature map synthesis
Engineering Applications of Artificial Intelligence ( IF 8 ) Pub Date : 2024-04-09 , DOI: 10.1016/j.engappai.2024.108391 Xiaotong Guo , Huijie Zhao , Shuwei Shao , Xudong Li , Baochang Zhang
Engineering Applications of Artificial Intelligence ( IF 8 ) Pub Date : 2024-04-09 , DOI: 10.1016/j.engappai.2024.108391 Xiaotong Guo , Huijie Zhao , Shuwei Shao , Xudong Li , Baochang Zhang
|
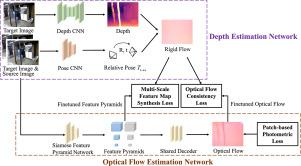
Self-supervised monocular depth estimation methods have been increasingly given much attention due to the benefit of not requiring large, labelled datasets. Such self-supervised methods require high-quality salient features and consequently suffer from severe performance drop for indoor scenes, where low-textured regions dominant in the scenes are almost indiscriminative. To address the issue, we propose a self-supervised indoor monocular depth estimation framework called FDepth. A self-supervised optical flow estimation network is introduced to supervise depth learning. To improve optical flow estimation performance in low-textured areas, only some patches of points with more discriminative features are adopted for finetuning based on our well-designed patch-based photometric loss. The finetuned optical flow estimation network generates high-accuracy optical flow as a supervisory signal for depth estimation. Correspondingly, an optical flow consistency loss is designed. Multi-scale feature maps produced by finetuned optical flow estimation network perform warping to compute feature map synthesis loss as another supervisory signal for depth learning. Experimental results on the NYU Depth V2 dataset demonstrate the effectiveness of the framework and our proposed losses. To evaluate the generalization ability of our FDepth, we collect a Campus Indoor depth dataset composed of approximately 1500 points selected from 99 images in 18 scenes. Zero-shot generalization experiments on 7-Scenes dataset and Campus Indoor achieve accuracy of 75.8% and 76.0% respectively. The accuracy results show that our model can generalize well to monocular images captured in unknown indoor scenes.
中文翻译:

F[公式省略]Depth:通过光流一致性和特征图合成进行自监督室内单目深度估计
由于不需要大型标记数据集的优点,自监督单目深度估计方法越来越受到关注。这种自监督方法需要高质量的显着特征,因此在室内场景中性能会严重下降,其中场景中占主导地位的低纹理区域几乎是不加区别的。为了解决这个问题,我们提出了一种名为 FDepth 的自监督室内单目深度估计框架。引入自监督光流估计网络来监督深度学习。为了提高低纹理区域的光流估计性能,基于我们精心设计的基于补丁的光度损失,仅采用一些具有更具辨别性特征的点补丁进行微调。微调光流估计网络生成高精度光流作为深度估计的监控信号。相应地,设计了光流一致性损失。由微调光流估计网络生成的多尺度特征图执行扭曲来计算特征图合成损失,作为深度学习的另一个监督信号。 NYU Depth V2 数据集上的实验结果证明了该框架的有效性和我们提出的损失。为了评估 FDepth 的泛化能力,我们收集了一个 Campus Indoor 深度数据集,该数据集由从 18 个场景的 99 张图像中选出的约 1500 个点组成。 7-Scenes 数据集和 Campus Indoor 上的零样本泛化实验分别实现了 75.8% 和 76.0% 的准确率。准确性结果表明,我们的模型可以很好地推广到在未知室内场景中捕获的单目图像。
更新日期:2024-04-09
中文翻译:
F[公式省略]Depth:通过光流一致性和特征图合成进行自监督室内单目深度估计
由于不需要大型标记数据集的优点,自监督单目深度估计方法越来越受到关注。这种自监督方法需要高质量的显着特征,因此在室内场景中性能会严重下降,其中场景中占主导地位的低纹理区域几乎是不加区别的。为了解决这个问题,我们提出了一种名为 FDepth 的自监督室内单目深度估计框架。引入自监督光流估计网络来监督深度学习。为了提高低纹理区域的光流估计性能,基于我们精心设计的基于补丁的光度损失,仅采用一些具有更具辨别性特征的点补丁进行微调。微调光流估计网络生成高精度光流作为深度估计的监控信号。相应地,设计了光流一致性损失。由微调光流估计网络生成的多尺度特征图执行扭曲来计算特征图合成损失,作为深度学习的另一个监督信号。 NYU Depth V2 数据集上的实验结果证明了该框架的有效性和我们提出的损失。为了评估 FDepth 的泛化能力,我们收集了一个 Campus Indoor 深度数据集,该数据集由从 18 个场景的 99 张图像中选出的约 1500 个点组成。 7-Scenes 数据集和 Campus Indoor 上的零样本泛化实验分别实现了 75.8% 和 76.0% 的准确率。准确性结果表明,我们的模型可以很好地推广到在未知室内场景中捕获的单目图像。


























 京公网安备 11010802027423号
京公网安备 11010802027423号