Applied Intelligence ( IF 5.3 ) Pub Date : 2024-04-11 , DOI: 10.1007/s10489-024-05444-8 Kai Zeng , Zixin Wan , HongWei Gu , Tao Shen
|
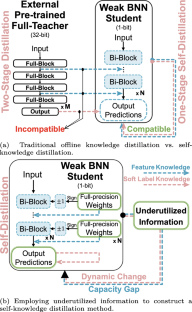
Binarization efficiently compresses full-precision convolutional neural networks (CNNs) to achieve accelerated inference but with substantial performance degradations. Self-knowledge distillation (SKD) can significantly improve the performance of a network by inheriting its own advanced knowledge. However, SKD for binary neural networks (BNNs) remains underexplored because the binary characteristics of weak BNNs limit their ability to act as effective teachers, hindering their ability to learn as students. In this study, a novel SKD-BNN framework is proposed by using two pieces of underutilized information. Full-precision weights, which are applied for gradient transfer, concurrently distill the feature knowledge of the teacher with high-level semantics. A value-swapping strategy minimizes the knowledge capacity gap, while the channel-spatial difference distillation loss promotes feature transfer. Moreover, historical output predictions generate a concentrated soft-label bank, providing abundant intra- and inter-category similarity knowledge. Dynamic filtering ensures the correctness of the soft labels during training, and the label-cluster loss enhances the summarization ability of the soft-label bank within the same category. The developed methods excel in extensive experiments, achieving state-of-the-art accuracy of 93.0% on the CIFAR-10 dataset, which is equivalent to that of full-precision CNNs. On the ImageNet dataset, the accuracy improves by 1.6% with the widely adopted IR-Net. It is emphasized that for the first time, the proposed method fully explores the underutilized information contained in BNNs and conducts an effective SKD process, enabling weak BNNs to serve as competent self-teachers and proficient students.
中文翻译:
从未充分利用的信息中衍生出自我知识蒸馏增强的二元神经网络
二值化可有效压缩全精度卷积神经网络 (CNN),以实现加速推理,但性能会大幅下降。自知识蒸馏(SKD)可以通过继承自身的先进知识来显着提高网络的性能。然而,二元神经网络 (BNN) 的 SKD 仍未得到充分研究,因为弱 BNN 的二元特征限制了它们作为有效教师的能力,阻碍了它们作为学生学习的能力。在本研究中,利用两条未充分利用的信息提出了一种新颖的 SKD-BNN 框架。用于梯度转移的全精度权重同时提炼出具有高级语义的教师的特征知识。价值交换策略最大限度地减少了知识容量差距,而通道空间差异蒸馏损失则促进了特征转移。此外,历史输出预测生成集中的软标签库,提供丰富的类别内和类别间相似性知识。动态过滤保证了训练过程中软标签的正确性,标签簇损失增强了软标签库在同一类别内的概括能力。所开发的方法在广泛的实验中表现出色,在 CIFAR-10 数据集上实现了 93.0% 的最先进准确率,相当于全精度 CNN 的准确率。在 ImageNet 数据集上,随着广泛采用的 IR-Net,准确率提高了 1.6%。需要强调的是,该方法首次充分挖掘了 BNN 中未充分利用的信息,并进行有效的 SKD 过程,使弱 BNN 能够成为有能力的自学教师和熟练的学生。


























 京公网安备 11010802027423号
京公网安备 11010802027423号