Autonomous Robots ( IF 3.5 ) Pub Date : 2024-04-17 , DOI: 10.1007/s10514-024-10160-w Xiaoying Wang , Tong Zhang
|
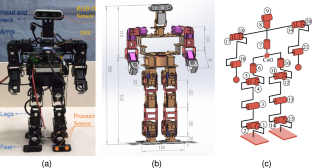
Humanoid robots have strong adaptability to complex environments and possess human-like flexibility, enabling them to perform precise farming and harvesting tasks in varying depths of terrains. They serve as essential tools for agricultural intelligence. In this article, a novel method was proposed to improve the robustness of autonomous navigation for humanoid robots, which intercommunicates the data fusion of the footprint planning and control levels. In particular, a deep reinforcement learning model - Proximal Policy Optimization (PPO) that has been fine-tuned is introduced into this layer, before which heuristic trajectory was generated based on imitation learning. In the RL period, the KL divergence between the agent’s policy and imitative expert policy as a value penalty is added to the advantage function. As a proof of concept, our navigation policy is trained in a robotic simulator and then successfully applied to the physical robot GTX for indoor multi-mode navigation. The experimental results conclude that incorporating imitation learning imparts anthropomorphic attributes to robots and facilitates the generation of seamless footstep patterns. There is a significant improvement in ZMP trajectory in y-direction from the center by 21.56% is noticed. Additionally, this method improves dynamic locomotion stability, the body attitude angle falling between less than ± 5.5\(^\circ \) compared to ± 48.4\(^\circ \) with traditional algorithm. In general, navigation error is below 5 cm, which we verified in the experiments. It is thought that the outcome of the proposed framework presented in this article can provide a reference for researchers studying autonomous navigation applications of humanoid robots on uneven ground.
中文翻译:
仿人机器人导航的模仿行为强化学习:同步规划和控制
仿人机器人对复杂环境具有很强的适应能力,并具有类似人类的灵活性,使其能够在不同深度的地形中执行精确的耕作和收获任务。它们是农业情报的重要工具。在本文中,提出了一种新方法来提高仿人机器人自主导航的鲁棒性,该方法可实现足迹规划和控制级别的数据融合的相互通信。特别是,该层引入了经过微调的深度强化学习模型——近端策略优化(PPO),在此之前基于模仿学习生成启发式轨迹。在RL期间,代理策略和模仿专家策略之间的KL散度作为价值惩罚被添加到优势函数中。作为概念证明,我们的导航策略在机器人模拟器中进行训练,然后成功应用于物理机器人GTX进行室内多模式导航。实验结果得出结论,结合模仿学习赋予机器人拟人化属性,并促进无缝脚步模式的生成。注意到从中心 y 方向的 ZMP 轨迹显着改善了 21.56%。此外,该方法提高了动态运动稳定性,与传统算法的±48.4\ (^\circ\)相比,身体姿态角落在±5.5 \ (^\circ\)之间。一般来说,导航误差在5厘米以下,我们在实验中验证了这一点。本文提出的框架结果可以为研究人形机器人在不平坦地面上自主导航应用的研究人员提供参考。


























 京公网安备 11010802027423号
京公网安备 11010802027423号