Journal of Ambient Intelligence and Humanized Computing ( IF 3.662 ) Pub Date : 2024-04-18 , DOI: 10.1007/s12652-024-04787-x Xiangdong Meng , Hong Liu , Wenhao Li
|
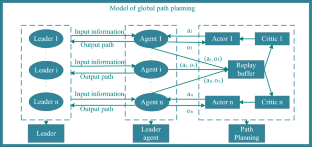
Deep reinforcement learning (DRL) is suitable for solving complex path-planning problems due to its excellent ability to make continuous decisions in a complex environment. However, the increase in the population size in the crowd evacuation path-planning problem causes a substantial computational burden for the algorithm, which leads to an unsatisfactory efficiency of the current DRL algorithm. This paper presents a path planning method based on DRL for crowd evacuation to solve the problem. First, we divide crowds into groups based on their relationship and distance from each other and select leaders from them. Next, we expand the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) to propose an Optimized Multi-Agent Deep Deterministic Policy Gradient (OMADDPG) algorithm to obtain the global evacuation path. The OMADDPG algorithm uses the Cross-Entropy Method (CEM) to optimize policy and improve the neural network’s training efficiency by applying the Data Pruning (DP) algorithm. In addition, the social force model is improved, incorporating the relationship between individuals and psychological factors into the model. Finally, this paper combines the improved social force model and the OMADDPG algorithm. The OMADDPG algorithm transmits the path information to the leaders. Pedestrians in the environment are driven by the improved social force model to follow the leaders to complete the evacuation simulation. The method can use a leader to guide pedestrians safely arrive the exit and reduce evacuation time in different environments. The simulation results prove the efficiency of the path planning method.
中文翻译:
一种基于深度强化学习的人群疏散路径规划方法
深度强化学习(DRL)由于其在复杂环境中做出持续决策的出色能力,适合解决复杂的路径规划问题。然而,人群疏散路径规划问题中人口规模的增加给算法带来了巨大的计算负担,导致当前DRL算法的效率不理想。针对这一问题,本文提出一种基于DRL的人群疏散路径规划方法。首先,我们根据人群之间的关系和距离将人群分为几组,并从中选出领导者。接下来,我们扩展多智能体深度确定性策略梯度(MADDPG),提出优化多智能体深度确定性策略梯度(OMADDPG)算法来获得全局疏散路径。 OMADDPG算法采用交叉熵法(CEM)来优化策略,并通过应用数据剪枝(DP)算法来提高神经网络的训练效率。此外,改进了社会力模型,将个体之间的关系和心理因素纳入模型中。最后,本文将改进的社会力模型与OMADDPG算法相结合。 OMADDPG 算法将路径信息传输给领导者。环境中的行人在改进的社会力模型的驱动下跟随领导者完成疏散模拟。该方法可以在不同环境下利用引导员引导行人安全到达出口,减少疏散时间。仿真结果证明了路径规划方法的有效性。


























 京公网安备 11010802027423号
京公网安备 11010802027423号