Journal of Ambient Intelligence and Humanized Computing ( IF 3.662 ) Pub Date : 2024-04-20 , DOI: 10.1007/s12652-024-04779-x Pengjie Tang , Hong Rao , Ai Zhang , Yunlan Tan
|
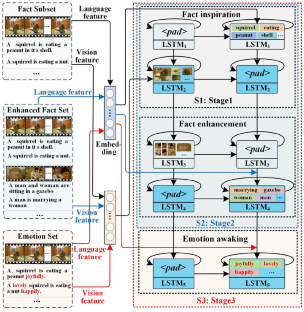
Video description aims to translate the visual content in a video with appropriate natural language. Most of current works only focus on the description of factual content, paying insufficient attention to the emotions in the video. And the sentences always lack flexibility and vividness. In this work, a fact enhancement and emotion awakening based model is proposed to describe the video, making the sentence more attractive and colorful. The strategy of deep incremental leaning is employed to build a multi-layer sequential network firstly, and multi-stage training method is used to sufficiently optimize the model. Secondly, the modules of fact inspiration, fact reinforcement and emotion awakening are constructed layer by layer to discovery more facts and embed emotions naturally. The three modules are cumulatively trained to sufficiently mine the factual and emotional information. Two public datasets including EmVidCap-S and EmVidCap are employed to evaluate the proposed model. The experimental results show that the performance of the proposed model is superior to not only the baseline models, but also the other popular methods.
中文翻译:
具有事实强化和情感唤醒的视频情感描述
视频描述旨在用适当的自然语言翻译视频中的视觉内容。目前的作品大多只注重事实内容的描述,对视频中的情感关注不够。而且句子总是缺乏灵活性和生动性。在这项工作中,提出了基于事实增强和情感唤醒的模型来描述视频,使句子更加有吸引力和丰富多彩。首先采用深度增量学习策略构建多层序列网络,并采用多阶段训练方法对模型进行充分优化。其次,层层构建事实启发、事实强化、情感唤醒模块,发现更多事实,自然嵌入情感。三个模块经过累积训练,可以充分挖掘事实和情感信息。使用包括 EmVidCap-S 和 EmVidCap 在内的两个公共数据集来评估所提出的模型。实验结果表明,所提出的模型的性能不仅优于基线模型,而且优于其他流行的方法。


























 京公网安备 11010802027423号
京公网安备 11010802027423号