Environmental Science and Pollution Research ( IF 5.8 ) Pub Date : 2024-04-23 , DOI: 10.1007/s11356-024-33281-2 Umar Alfa Abubakar , Gul Sanga Lemar , Al-Amin Danladi Bello , Aliyu Ishaq , Aliyu Adamu Dandajeh , Zainab Toyin Jagun , Mohamad Rajab Houmsi
|
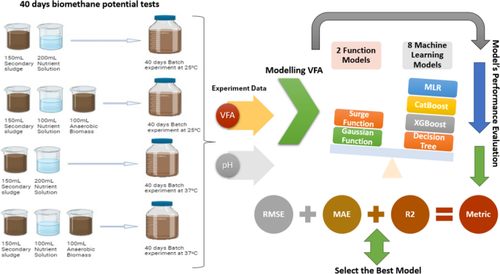
This study evaluates models for predicting volatile fatty acid (VFA) concentrations in sludge processing, ranging from classical statistical methods (Gaussian and Surge) to diverse machine learning algorithms (MLAs) such as Decision Tree, XGBoost, CatBoost, LightGBM, Multiple linear regression (MLR), Support vector regression (SVR), AdaBoost, and GradientBoosting. Anaerobic bio-methane potential tests were carried out using domestic wastewater treatment primary and secondary sludge. The tests were monitored over 40 days for variations in pH and VFA concentrations under different experimental conditions. The data observed was compared to predictions from the Gaussian and Surge models, and the MLAs. Based on correlation analysis using basic statistics and regression, the Gaussian model appears to be a consistent performer, with high R2 values and low RMSE, favoring precision in forecasting VFA concentrations. The Surge model, on the other hand, albeit having a high R2, has high prediction errors, especially in dynamic VFA concentration settings. Among the MLAs, Decision Tree and XGBoost excel at predicting complicated patterns, albeit with overfitting issues. This study provides insights underlining the need for context-specific considerations when selecting models for accurate VFA forecasts. Real-time data monitoring and collaborative data sharing are required to improve the reliability of VFA prediction models in AD processes, opening the way for breakthroughs in environmental sustainability and bioprocessing applications.
中文翻译:
污泥厌氧消化中挥发性脂肪酸浓度建模的传统和机器学习方法的评估:潜力和挑战
本研究评估了预测污泥处理中挥发性脂肪酸 (VFA) 浓度的模型,范围从经典统计方法(高斯和 Surge)到各种机器学习算法 (MLA),例如决策树、XGBoost、CatBoost、LightGBM、多元线性回归( MLR)、支持向量回归(SVR)、AdaBoost 和 GradientBoosting。利用生活污水处理初、二级污泥进行厌氧生物甲烷潜力测试。在 40 天内,对不同实验条件下 pH 值和 VFA 浓度的变化进行了监测。将观察到的数据与高斯模型、Surge 模型以及 MLA 的预测进行比较。基于使用基本统计和回归的相关分析,高斯模型似乎表现一致,具有高R 2值和低 RMSE,有利于预测 VFA 浓度的精度。另一方面,Surge 模型虽然具有较高的R 2,但具有较高的预测误差,特别是在动态 VFA 浓度设置中。在 MLA 中,决策树和 XGBoost 擅长预测复杂模式,尽管存在过度拟合问题。这项研究提供了见解,强调在选择准确的 VFA 预测模型时需要考虑具体情况。需要实时数据监控和协作数据共享来提高 AD 过程中 VFA 预测模型的可靠性,为环境可持续性和生物加工应用的突破开辟道路。


























 京公网安备 11010802027423号
京公网安备 11010802027423号