Sādhanā ( IF 1.6 ) Pub Date : 2024-04-25 , DOI: 10.1007/s12046-024-02497-w Vipin Jain , Kanchan Lata Kashyap
|
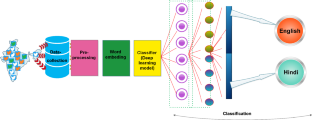
The process of determining native tongue of document is known as language identification. This work presents word level language identification of text as English or Hindi. Experimental analysis is performed on dataset collected from Twitter. In the first step, collected data is preprocessed by applying natural language processing techniques. Ensemble word embedding technique is proposed by ensembling four word embedding techniques namely, (i) Word2Vec, (ii) Embeddings from Language Model, (iii) Global Vectors, and (iv) FastText. Proposed word embedding approach is applied on preprocessed data to get enhanced word vector space for language identification. Finally, classification of text as Hindi or English is performed by four heterogeneous deep learning models namely, (i) Convolution Neural Network (CNN), (ii) Long Short Term Memory (LSTM), (iii) Hybrid model of CNN and LSTM, and (iv) Hybrid model of Bidirectional Long Short-Term Memory and Gated Recurrent Unit. Proposed hybrid model gives highest 96.05%, 95.13%, 94.21%, and 97.67% precision, F-score, sensitivity, and accuracy, respectively. Outcome obtained by the proposed model is higher as compare to single deep learning approach.
中文翻译:
使用集成深度学习模型改进词向量空间以进行语言识别
确定文档的母语的过程称为语言识别。这项工作提出了英语或印地语文本的字级语言识别。对从 Twitter 收集的数据集进行实验分析。第一步,通过应用自然语言处理技术对收集的数据进行预处理。集成词嵌入技术是通过集成四种词嵌入技术提出的,即(i)Word2Vec,(ii)来自语言模型的嵌入,(iii)全局向量和(iv)FastText。所提出的词嵌入方法应用于预处理数据,以获得用于语言识别的增强词向量空间。最后,通过四种异构深度学习模型将文本分类为印地语或英语,即(i)卷积神经网络(CNN),(ii)长短期记忆(LSTM),(iii)CNN和LSTM的混合模型, (iv) 双向长短期记忆和门控循环单元的混合模型。所提出的混合模型分别提供最高的 96.05%、95.13%、94.21% 和97.67% 的精度、F 分数、灵敏度和准确度。与单一深度学习方法相比,所提出的模型获得的结果更高。


























 京公网安备 11010802027423号
京公网安备 11010802027423号